

This research was initiated accidentally. After “mini-dumping” all active Chrome.exe processes for another research project, I decided to see if a password that I recently typed in the browser appears in any of these dumps. I was surprised to see that the password was stored, in clear-text format, at several separate locations in the memory of two of these processes.
I should not have been surprised since similar issues were reported previously (e.g., in a blog post from 2015 by Satyam Singh) but I was not aware of these previous reports at the time.
I decided to take a deeper look and see what types of sensitive data are stored in clear-text format and if that information can be effectively (within a reasonable time) extracted directly from the browser’s memory. The results were surprising (to me) — and quite concerning!
TL; DR
- Credential data (URL/username/password) is stored in Chrome’s memory in clear-text format. In addition to data that is dynamically entered when signing into specific web applications, an attacker can cause the browser to load into memory all the passwords that are stored in the password manager (“Login Data” file).
- Cookies’ data (cookies’ value + properties) is stored in Chrome’s memory in clear-text format (when the relevant application is active). This includes sensitive session cookies.
- This information can be extracted effectively by a standard (non-elevated) process running in the local machine and performing direct access to Chrome’s memory (using OpenProcess + ReadProcessMemory APIs).
- The extracted data can be used to hijack users’ accounts even when they are protected by an MFA mechanism (using the “session-cookies” data).
- Sample session hijacking was “POC-ed” for Gmail, OneDrive and GitHub.
- Similar weaknesses were seen in the Microsoft Edge browser (and will be found, presumably, in other browsers that are based on the Chromium engine).
- This blog describes the direct memory access attack on the browser. There are other published methods of stealing this sensitive data. My next blog post shall provide a broader description of known “credential-stealing from browsers” attack techniques and will discuss possible mitigations for all of them.
- Why this is a significant issue: If one accepts the “assume breach” paradigm, then [all] the weaknesses in the way Chromium-based browsers treat sensitive credential data should be considered a major security risk. Mitigation should treat all these weaknesses.
- “Better Together:” We shared the results of this research with CrowdStrike. This collaboration helped improve the endpoint protection products of both companies.
What Does ‘Private’ Mean to You? A First Look Inside Chrome’s Memory
The Process Hacker tool (by Wen Jia Liu) proved very useful in this research. If you suspect that a specific string is stored in the memory of a process, a fast way to look for it is:
- Open that process in ProcessHacker.exe
- Select the “Memory” option
- Activate the “Strings” sub-option
- Select the “Filter” option and key the string you are looking for in the “contains…” frame
Here is an example output generated when I looked for a known password (don’t worry, I changed it):
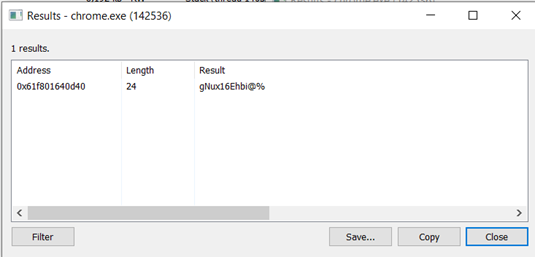
If you return to the memory layout shown (when you selected the “Memory” option) you will find out this string is in a memory section of type Private:
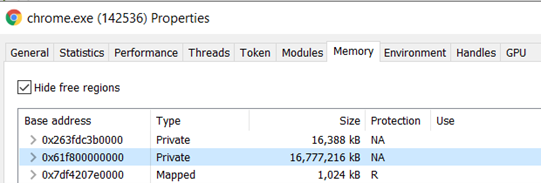
And looking deeper inside that memory chunk, the password is stored inside a memory section of type Private: Commit:
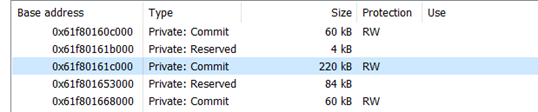
Question: What does “Private” mean to you?
According to MSDN, Private memory (MEMORY_BASIC_INFORMATION Type=MEM_PRIVATE) means:

One could think that data stored in such memory pages is not accessible to any other process. Surprisingly, such pages cannot be part of a “shared memory,” but other processes have no problem reading the data in them (via ReadProcessMemory API).
You already saw proof of this behavior: ProcessHacker.exe above ran as a standard process and has no problem accessing this data!
If these pages were really private, the attack vector described here would not be possible. I wonder if the creators of Chromium might have thought (at some point) that the sensitive data is safe when stored in Private memory.
A Needle in a Haystack? A Deeper Look Into Chrome’s Memory
Finding a known string in the browser’s memory is not a big deal, of course. How about finding unknown strings? I decided to try and find the sensitive data only by looking in the process memory (without trying to analyze the program’s open-source code).
The Chromium memory layout appears like it was designed to be a “haystack,” making it difficult to find and “make sense” of the stored data (specifically sensitive strings such as passwords and cookies’ values). I also encountered various honeypots that look like they were created intentionally to generate false-positive identifications of clear-text passwords. Among the difficulties were:
- A relatively large number of browser processes (e.g., chrome.exe).
- Each process has a large quantity of virtual memory allocated (some with > 230GB).
- The memory of each process is made up of many (sometimes hundreds) of “disjointed” small, committed memory sections separated by “reserved” sections.
- Large memory “composed” sections that include many disjointed sections as described above that are virtually “empty” (not “really” used).
- Strings (substrings of actual strings) that look like passwords or cookie values (either intentionally or not).
- Scattering of items belonging to one logical “record” (e.g., URL + username + password) into distanced memory locations.
It could be that it all looked like hiding (“obfuscation”) attempts while just being the result of normal operation. As mentioned above, I did not look at the code, but I give them credit for trying to hide sensitive data.
Clear-text Credential Data Types Extracted From Chrome’s Memory
It turns out that effectively extracting clear text credential data from the browser’s memory can be achieved quite easily by a standard non-privileged process. By effectively, I mean:
- It uses a reasonable amount of the computer’s resources (CPU power, memory).
- Execution completes in a reasonable time.
- “True positive” findings are not completely drowned out by false-positive items.
Note: As we come to sections that describe the POC programs, I know most of the readers will expect technical details and source code snippets of the critical functions. This information will not be disclosed for reasons explained in the concluding sections of this blog post. POC programs have been developed to extract the following types of information:
a) Username + password used when signing into a targeted web application
The program waits for the user to sign into a specific web application (e.g., Gmail, OneDrive, GitHub, etc.) and then analyzes captured memory snapshots to identify the username and password used to sign into the application.
This is a bit like what an effective key-logger can achieve, with the important difference that previously stored passwords (e.g., in the browser’s password manager tool), which completely bypass a key-logger that was not running when they were initially defined, will be discovered by our program.
The program looks at the differences between snapshots taken before and immediately after signing in, and looks for new strings that appear only in the “after” snapshots and that look “like” potential username and password strings.
Note: This was the most complex POC program developed in this research, and it generated a fair number of false-positive results, since quite a lot of new strings appear in the “after” memory snapshot.
Filtering out these false-positive cases is possible (e.g., by identifying common “words” that appear in the sign-in process) and can be continuously improved if one wants to put in the effort. Ironically, the stronger the password, the easier it is to separate it from “noise” false positive cases (e.g., a string of 10 characters composed of lower case and uppercase characters, digits and special signs is more likely to be a password than a seven-character string with only lower-case characters).
Demo 0-DynamicGmailPasswordCatch
b) URL + Username + Password automatically loaded into memory during browser’s startup
Some entries in the “Login Data” file (where Chromium stores saved passwords) are automatically loaded into memory when the browser is started. While not all entries from “Login Data” are necessarily loaded, the most recently used (and most interesting?) ones are.
The passwords in the “Login Data” DB are DPAPI-encrypted, but when they are “scattered” into the memory, they are saved in clear-text format.
Unlike the previous case (“a” above), here it is enough to analyze one set of snapshots, since the loaded credential data stays statically in the memory.
We have developed an effective POC program that extracts this data from memory. A small number of false-positive items might be generated. Again, the algorithm that filters out the false-positive cases can be significantly and continuously improved.
Demo 1-AutoLoadedPasswords
c) All URL + username + password records stored in Login Data
It is possible to make the Password Manager feature of the browser load all its stored records into memory. The POC program we developed can extract all the loaded records. The sensitive data, in this case, is arranged in a structure that is easy to recognize. Therefore, the program has high confidence in the extracted data and, in most cases, will have little to no False-Positive entries.
Credit: Anatoly Kardash, a senior director in CyberArk’s R&D department, has drawn my attention to the fact that all the saved password records are loaded into Chrome’s memory in this case. He also helped me discover and analyze various Chromium memory layouts.
Demo 2-AllSavedPasswords
d) All cookies belonging to a specific web application (including session cookies)
The program waits for the user to sign into a specific application (e.g., Gmail, OneDrive, GitHub, etc.). When the application session is active, the program can extract from Chrome’s memory all the cookies that belong to this session. These stolen cookies can be uploaded into the browser on a different machine and the session can be stolen (bypassing any MFA mechanisms).
When the stolen cookies are used to hijack the session, typical applications (e.g., Gmail) do not recognize that the connection is made from a new device or a new location. This is because the sign-in process is completely bypassed. Based on the contents of the cookies, the application assumes this is a continuation of a previously authenticated session.
It is important to note that some applications encourage their users not to sign out of the application. Gmail’s session cookies, for example, have an expiration period of two years from the time they were first generated. Similarly, Microsoft OneDrive has recently started to suggest to its web users that they need not sign out of their session. In these cases, an attacker stealing the session cookies may “share” the account with the real owner for an awfully long time.
As in case “c” above, the attack program has a high degree of confidence in its findings, and therefore false-positive cases are exceedingly rare.
Demo 3-GmailSessionHijacking
Demo 4-OneDriveSessionHijacking
Responsible Disclosure and Vendor Response
I reported this issue to Google on July 29, 2021:

The report included a detailed POC of Gmail session hijacking, including the source code of the program that extracts cookies from Chrome’s memory.
The response (WontFix) from Chromium.org came back very quickly:

This response is not very surprising, since similar responses have been received by other reports of similar “assume breach” vulnerabilities.
And 14 weeks later, Chromium made my report public:

So, to sum up the responsible disclosure:
Chromium.org stated they will not fix issues related to physical local attacks since “there is no way for Chrome (or any application) to defend against a malicious user who has managed to log into your device as you” (here). While this statement is probably true in general (especially if you assume the attacker can get administrator privileges), I believe it should not be so easy to steal sensitive credentials as it is today. Therefore, as mentioned above, my next blog post will suggest several mitigation techniques that will make it harder to execute the attack.
Over time, I did observe some changes that may have been “mitigation” attempts:
- Approximately one month after the responsible disclosure, my program failed to extract cookies data. It turned out that the general memory layout had been modified (in Chrome as well as in Edge).
- I generalized my program to accommodate for this and similar changes. Some two months later, it failed again. This time, the location of the “sensitive” data had been changed (again, for Chrome and Edge simultaneously).
- I also discovered (after many months of successful cookies-stealing research) that suddenly for some of the cookies (selected randomly?), elements of the cookie definition were scattered in memory like the Login credential elements.
Whether these were specific mitigation attempts or part of a continuous “let’s-make-memory-access harder” procedure, they are quite weak, since it is quite simple to generalize an accessing program for these types of modifications.
Why Demo Videos (and no Technical Details of the POC Programs)
The initial POC program was developed for Version 91.0.4472.164 of Chrome:

The POC programs in the demo videos are accessing version 96.0.4664.45 of Chrome:

As mentioned above, modifications in the memory layout, as well as in the way cookies’ values are stored in the memory, have been found since we responsibly disclosed the issue. However, these modifications were very general and did not make “credential-stealing” significantly harder.
Our purpose for this blog post was to raise awareness of this issue and help organizations improve their security around this and similar browser vulnerabilities. Since the vulnerability is not planned to be fixed, sharing a POC or source code will not promote this purpose, but instead could potentially cause harm or elevate related threats. Therefore, with responsibility to the community in mind, we decided not to publish a POC.
The mitigation method for this attack, which I will discuss in my next blog post, is general and protects from a wide range of attack techniques, including the ones used in the POC programs that extract data directly from Chrome’s memory.
CyberArk may, however, share the POC programs (including the source code) with other security vendors and browser maintainers who are interested in revamping their security of credentials handled by Chromium-based browsers. In that spirit, this research and the full POC details were shared with CrowdStrike and the details are available in CrowdStrike’s blog.
Author note: Thank you to Emmanuel Ouanounou from the CyberArk Labs team for his support on this research.






















