

Introduction
Who are you? That’s a hard question to answer. Many philosophers have been fascinated with this question for years.
Who are you in cyberspace?
Your digital identity is comprised of anything that is you. Starting with your tweets, the photos you post on Facebook and Instagram, the private emails you have on Gmail and even the blog post you write for work. Basically, all the things that make you you online.
What do all these examples have in common? All these types of digital identity data are technically controlled by conglomerates that, with a push of a button or even worse with an automated algorithm, can erase your digital identity. This happened not too long ago when Meta took over an artist’s Instagram account. It also occurred when Google allegedly mistakenly identified a person as a child abuser and disabled his account entirely.
Our current way of managing identity in cyberspace needs to change.
So, what else is there?
In 2009, a person known as Satoshi Nakamoto changed everything.
In this two-part blog post, we’ll discuss a (rather) new concept called Decentralized Identity (or DID), which utilizes Nakamoto’s original concepts for identity purposes.
In this first post, we’ll cover the basics of DID and will get a better understanding of how it works by looking at one implementation (the Identity Overly Network) and its security considerations.
In the next post, we’ll review the most popular DID network in production, Sovrin, and analyze a critical vulnerability (CVE-2022-31020) we’ve found in its implementation.
Decentralized Identity
DID is often presented as a technology that implements the self-sovereignty (or self-ownership) principle for identity. Simply put, it means your identity is controlled by you (and only you). DID does that by operating on top of a distributed ledger (or blockchain) that allows everyone to come to a consensus on their and others’ identities.
In DID, your identity is effectively and technically controlled by you, the same way you are the one controlling your Bitcoin wallet — not a centralized bank entity that probably technically controls your savings.
DID should have a few properties:
- A persistent unique identifier – It points to the identity and never changes.
- User controlled and owned – You physically own it and may revoke it at any time.
- Decentralized – No single authority determines the state of identities, and users have a consensus on the current state.
- Cryptographically verifiable – You can prove that you control the identity using cryptographic principles.
Let’s try to explain how DID works at a high level. A user creates a new identity by generating a public-private key pair. The user then publishes the public key to the DID blockchain. From this point on, the user can prove their identity by signing/encrypting data using their private key. Anyone in the DID network can verify that the data is from that user by checking it against the already-published public key. Since we’re working on some sort of blockchain, the public key is immutable, and everyone has a consensus on it. Finally, the user can rotate/revoke their identity at any time they choose by publishing a new public key or a revocation message to the blockchain.
The most basic DID system will need the following components:
- Distributed ledger/blockchain – that can store identity information and identity operations
- Nodes – that will handle those operations and can resolve identities (i.e., determine their current status)
- Client – any software that will help users operate in the system — a mobile app, CLI tool, SDK for developers, etc.
A DID system can be implemented in many ways and on top of many different blockchain technologies. As the usage of DID becomes more popular, we’ll probably see one or two implementations that will become “industry standard” and will serve most users, however, this is not currently the case. Therefore, we will have a look at two very different DID implementations.
Don’t feel disheartened if you don’t fully understand what DID is and how it works. The best way to learn is by looking at an example, and we’ll do just that in the next section.
Microsoft Entra Verified ID
The Basics
Not too long ago, Microsoft presented their take on a DID system — Microsoft Entra Verified ID (previously Azure Verifiable Credentials). It has now been released to the public but still with quite limited functionality. Having said that, it is one of the first DID systems that was developed by one of the biggest companies in the market, so it’s worth our attention.
Broadly speaking, Microsoft Entra Verified ID (Figure 1) is based on four main components:
- Bitcoin as a blockchain
- InterPlanetary File System (or IPFS) as storage
- Sidetree protocol as a blockchain scaling layer
- Identity Overly Network protocol (or ION) as an instance of Sidetree
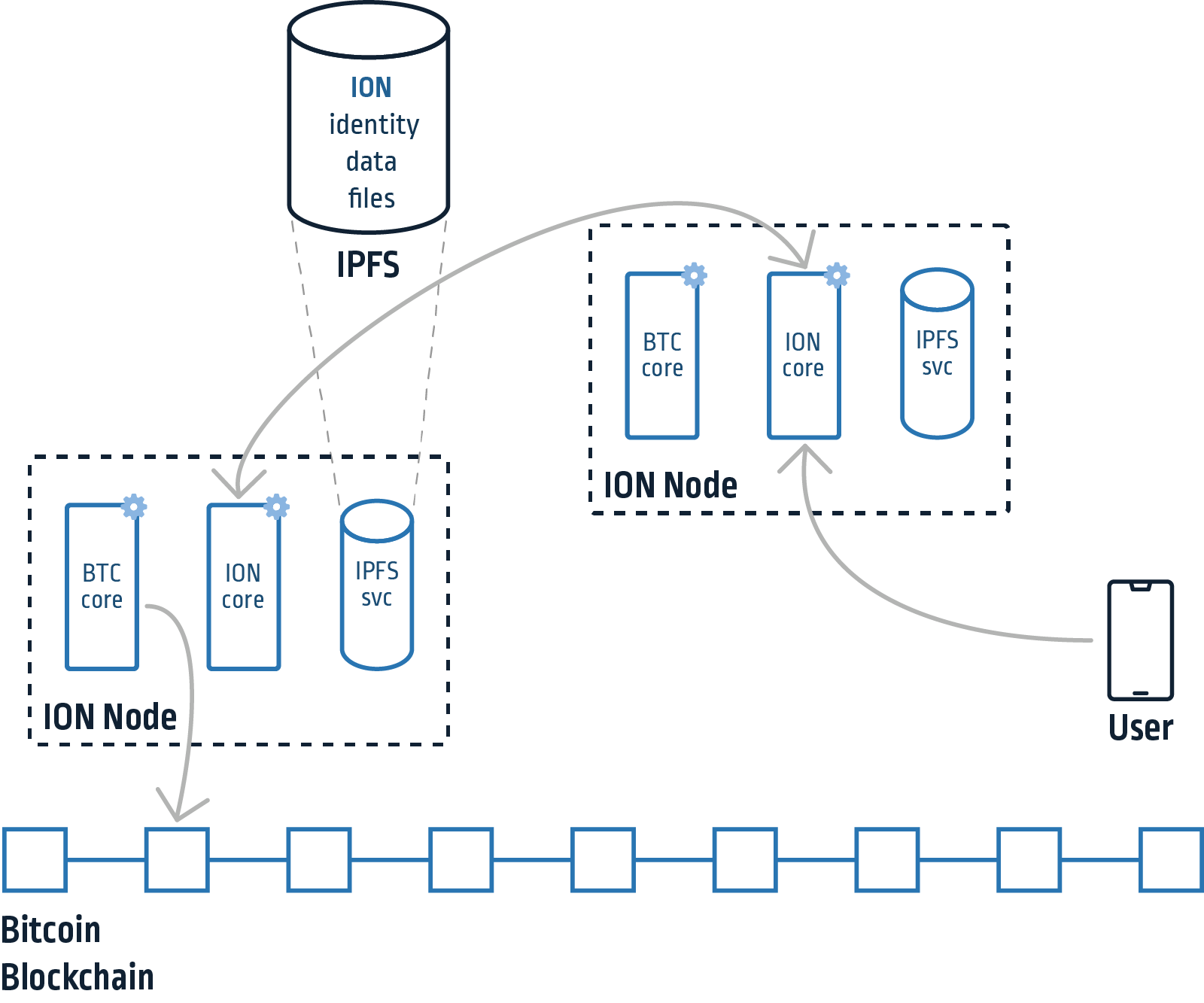
Figure 1 – ION overview
The heart of the system is the ION protocol, which is an instance of Sidetree. Sidetree is a DID second layer protocol that allows managing and storing identity operations on an existing blockchain. Examples of identity operations can be creating, updating or recovering one. Sidetree defines the identity operations and their appropriate requests, in addition to the file structure that contains the identity data in IPFS. IPFS indexes files using their CID (content identifier, a hash of the file’s content). Sidetree aggregates multiple identity operations and splits them into several files. Those files are then referenced by their CID in a root file which is finally “anchored” to the Bitcoin blockchain (Figure 2). Anchoring is done by simply writing its CID as data in an empty transaction. This makes the CID of the root file immutable as the blockchain, essentially “sealing” all the identity data in it and in files it references.
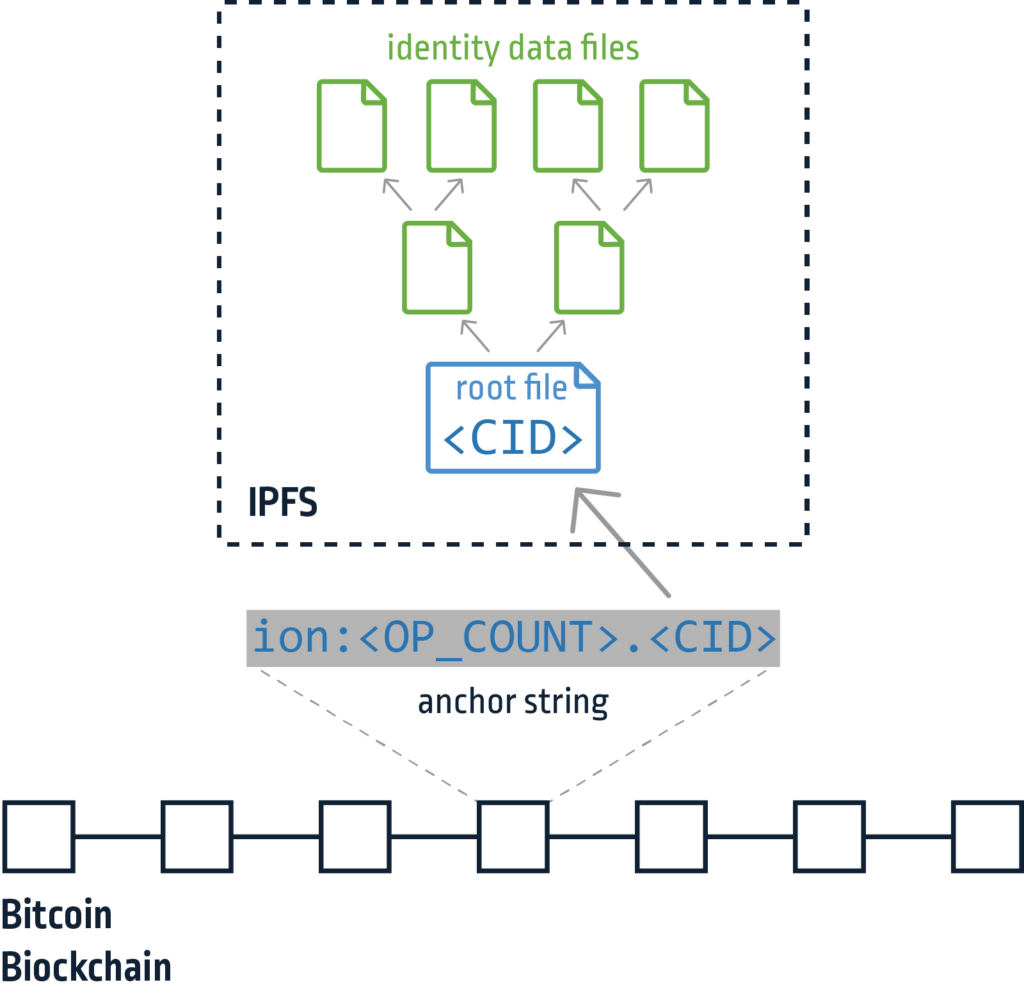
Figure 2 – ION identity data file anchoring
Once identity operations are “anchored” on the blockchain and then all the ION nodes and users can technically agree on when an operation had happened (not exactly when but more on their chronological order). That allows the identity to be treated as a conflict-free replicated data type (CRDT), which means that every node has a deterministic algorithm to build the current state of the identity based on all the previous operations and their chronological order.
When we reference the “ION Code,” similarly to Bitcoin, we mean the code of the nodes in the network. ION is written in Typescript, and you can find the node’s code on GitHub. However, it inherits most of the functionality from the blockchain-agnostic Sidetree repository.
ION nodes are essentially responsible for handling clients’ requests for performing identity operations (like the ones mentioned above) or resolving identities. Resolving an identity means iterating through all its past identity operations that have been anchored on the chain and determining its current state (i.e., the current public key, claims and assets associated with it). The nodes are also responsible for aggregating identity operations, splitting those into the protocol’s file structure and publishing them to IPFS. Nodes also monitor the Bitcoin chain to be notified of new files created by other nodes, which they fetch from IPFS.
Security Concerns
In general, when discussing DID security, we can address a few focus areas:
- Node’s Code – It can be either the code that handles identity operation requests or the one that resolves identities already in the system.
- Client-node trust – This issue is relevant to most decentralized systems. When you have an end user who can’t read and store the entire blockchain to validate a state (putting solutions like lightweight nodes and sharding aside until they are more prevalent), the user is trusting a node in the network to provide them with reliable information. This can be a problem if you have an attacker-controlled node or even an attacker intercepting communication between a user and a legitimate node. This way, an attacker can supply invalid information that does not represent the actual state in the blockchain.
- Private Key Storage – Every decentralized system is only as secure as the private keys that run it. Once a private key of an identity is stolen, the identity is compromised — no matter how secure the underlying system is.
These three focus areas are inherent to the nature of decentralized identity systems, but they aren’t the only ones we should consider. More traditional areas that aren’t unique to DID can also pose a major risk. These traditional risks can be post-authentication security, meaning what happens to your access tokens/session cookies after you logged in using DID, or even simple web vulnerabilities in any of the supporting components in a DID system.
Let’s see how two of these security concerns are reflected in in Microsoft Entra Verified ID.
Trust Issues
If we take a look at the ion-tools library, which is the official JS tool to enable developers to integrate ION DID into their applications, we can see a classic example of the client-node trust security concern.
By default, ion-tools resolve identities using beta.discover.did.microsoft.com. This is a node controlled and operated by Microsoft (i.e., a centralized entity with financial incentives). It means that the average developer who just wants to get everything up and running as quickly as possible will be getting identity information from Microsoft. They will have to trust that their node is reliable, wasn’t hacked and that the communication with it is not intercepted by a malicious attacker — thus, missing some of the security “promises” of a decentralized system.
To reiterate, this is not an issue that’s unique to ION; it’s relevant for many decentralized systems. People have been running Bitcoin nodes in their own homes for years now to ensure they get trustworthy information from the blockchain. Nonetheless, it is something that we need to be more aware of and must take into account when we shift identities toward the blockchain.
Commitment Issues
Before we can understand the issue, we need to know what a commitment scheme is. Since I’m not a better writer than the Wikipedians, we’ll let them do the heavy lifting:
“A commitment scheme is a cryptographic primitive that allows one to commit to a chosen value (or chosen statement) while keeping it hidden to others, with the ability to reveal the committed value later. Commitment schemes are designed so that a party cannot change the value or statement after they have committed to it: that is, commitment schemes are binding.
“A way to visualize a commitment scheme is to think of a sender as putting a message in a locked box and giving the box to a receiver. The message in the box is hidden from the receiver, who cannot open the lock themselves. Since the receiver has the box, the message inside cannot be changed — merely revealed if the sender chooses to give them the key at some later time.” – from Wikipedia
In our case, with ION (and in most cases when we discuss decentralized systems), it means that a user can create a commitment to their next public key by hashing the public key (or its hash) and publishing the final hash. When the user then wants to reveal or utilize the public key they committed to, they simply publish the value that had been hashed before. This allows anyone to verify that the value is, indeed, as committed by hashing their reveal value and checking that it’s the same as the hash they’ve published in the commitment.
ION supports the update identity operation that allows an identity to alter some of its properties. When creating an identity, you must create an update key pair and commit to it using the commitment scheme. Later, when an update is needed, the request should contain the reveal value of the last commitment to the update keys and a new commitment for the new set of update keys. Figure 3 shows how something like this looks:
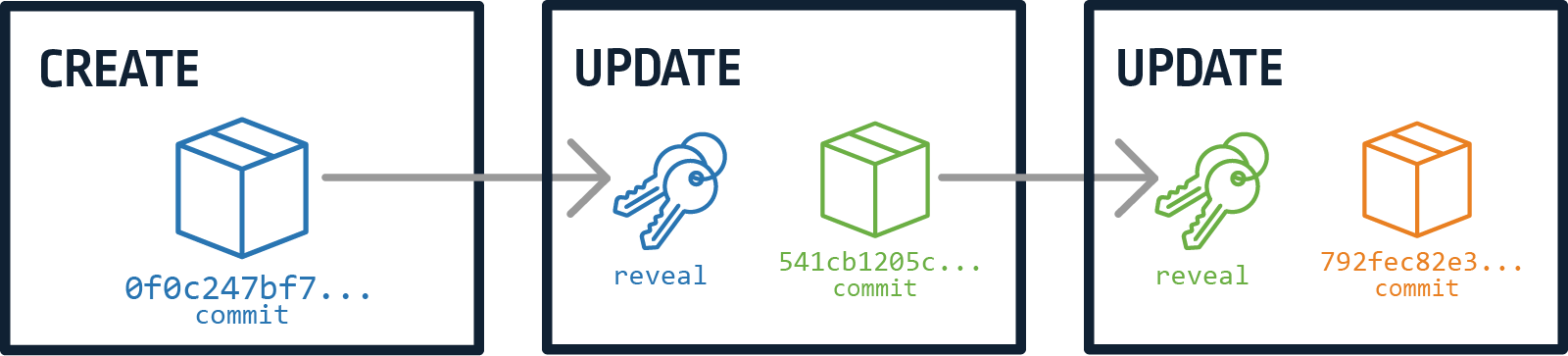
Figure 3 – Commit-reveal chain
If you’d like to know more about the specifics of the commitment scheme implementation in ION/Sidetree, please see the documentation.
The issue with this in ION was when the node tries to resolve a DID. Resolving basically means iterating through all of the identity operations related to that specific DID and determining its current status. In the resolving process, there is a function that applies all the update operations to the DID state by iterating over them using the commit-reveal chain. In other words, start with the create operation and get the first update key commitment. Then continue to the next update operation, which has the reveal value that matches to the previous commitment, and get the next update key commitment. Finally, continue iterating update operations until you no longer have a reveal value that matches the last update key commitment. This function can be found in the Sidetree source here.
Imagine an attacker constructing a commit-reveal chain, so that the last update operation update key commitment will match the reveal value of the first update operation. This way, you cause the node to enter an endless loop and never finish applying update operations and resolving the DID. Figure 4 illustrate this:
![]()
Figure 4 – Commit-reveal bug
DoS (Denial of Service) was the first thing that came to mind when we found this issue, but since Sidetree is written in Typescript — and due to some async magic done by Node.js internally — the node can enter an endless loop without increasing resource usage and still handle other user requests. This issue was reported by CyberArk Labs and fixed by the Sidetree team.
Conclusion
In this post, we’ve learned about DID concepts and how they can benefit us. We also discussed security considerations in DID and illustrated some of them using a specific DID implementation — Microsoft Entra Verified ID.
DID is an exciting technology that could allow everyone to really own and have control over their digital identity in the future. Since it’s still in its early stages, there are many security concerns that should be addressed. We understand that even though DID is supposed to be completely decentralized and more secure by using a blockchain, it exposes new attack surfaces, while still being potentially vulnerable to old, more traditional ones.
In the next post, we’ll review one of the most popular implementations of a DID system and walk through a critical vulnerability we discovered that allowed us to take it over.






















